it’s been a while since i’ve been deeply unsettled by the lack of resolution in a film, especially if the film’s conceit is overall preposterous. however, having just experienced the disquieting jouissance of such cinematic bombast last night, here i am, with a need to verbalize and process this tormentand whom else would i have to thank for this but my favorite member of the coppola family, nicolas cage, rumplestiltskin of the dramatic arts that he is. what, then, of the film that originated this long-winded introduction of this disquiet from theological and epistemological perspectives? it would be none other than KNOWING (2009, dir. alex proyas). spoilers follow, so be forewarned, lest ye find not your salvation.
i will not go into the plot in depth, but rather obliquely and nonlinearly. as such, the remainder of my writing assumes familiarity with the movie, and i’ll say up front that i’m providing an unalloyed recommendation. if i were to sum it up, however, its major thematic aspects relate to knowledge, faith, other-worldly forces, and the epistemic uncertainty that undergirds all of them. i’m struck by the movie’s refusal to take a clear stance on its major plot points, and thus places responsibility on the viewer to bring its own interpretation to bear. even in moments of it being at its most clear-cut — namely, the penultimate scene of ἀποκάλυψις, a razing of new york city by fire caused by climate change “solar flares” (i.e. “the wrath of god [that] burns against them” a la jonathan edwards) — an engaged viewer will most notably exclaim “what the actual fuck?” despite this ambiguity, this film is masterfully unsubtle, teeming with intertextual references to christian eschatology across multiple denominations and media, an embarassing use of skepticism as a kind of morality strawman-cum-punching bag, and extremely intense depictions of plausible(!) real-world disasters with mildly sickening CGI.
in terms of its focus on free will, KNOWING initially opens with the conceit of nicolas cage as john koestler, an MIT astrophysicist holding court in an undergrad class opposing free will with some sort of in-between hybrid of nomological determinism and predeterminism. it is here that john, says that he thinks “shit just happens,” and soon after we discover that he’s an atheist academic raised as preacher’s kid that had his latest crisis of faith after his wife died in a horrible hotel fire just days before his birthday. as he becomes obsessed with decoding and identifies the “real life” past and impending catastrophes, we see him bias towards predeterminism, but the as the truth itself is slowly revealed we are supposed to infer that every known cataclysm is delineated as a warning that something is coming for EE — everyone else. (it’s giving “this place is a message and is part of a system of messages; pay attention to it.” real “pick me” vibes.) as john dives into to try to stop or save people from terrible things happening (literally sticking his hands in flames to no avail in a failed attempt to save a plane crash victim), he is reminded and humbled by the great futility of his own existence, and his powerlessness in a cruel universe. why are all these things happening? and why do we know the exact predicted death toll?
as we start to realize this, it’s here that i see that the film begins shifting from predeterminism to predestination, and that perhaps, someone in the film is a messenger who will receive this message from the far beyond. it’s clear that the movie’s precocious child characters – john’s son, caleb, and abby, the granddaughter of lucinda, the girl who wrote the numbers that went into the time capsule – are the recipients of the gift of prophecy. but surprise: they’re also special in that they are the elect, bound to bearing the life of the world to come and imminently transported away by these celestial beings. and yet, are they angels? are they aliens? are they both? where does that leave poor old john? fucked in the end: he is not one of the elect. faced with his own spiritual damnation and physical annihilation, he returns to his ancestral home to be with his mildly estranged parents and heavily queer-coded nurse sister.
what’s fascinating to me about this movie is that it refuses to come out and really say what it’s about, and here’s where i disagree with roger ebert.1 we are supposed to be unsure whether they’re angels or aliens because their depiction is ambiguous. what fascinates me is that the lead writer, ryne pearson, also deliberately plays at that ambiguity.2 just the same, cage also believes it’s up to the viewer what to take from the movie, and expects that it might stimulate discussion.34 compare donald barthelme:
this is, i think, the relation of art to world. i suggest that art is always a meditation upon external reality rather than a representation of external reality or a jackleg attempt to “be” external reality.5
pearson is apparently a dedicated Catholic, too.6 these aspects combined make it also all the more fascinating to me that the movie’s themes feel particularly Calvinist: despite our faith and good works, most of us are truly and undeniably bound to suffer. yet as john says goodbye to caleb, and both as foreshadowed by john’s phone conversation to tell his father that the end is nigh and in the koestler family barbecue incineration and damnation, there is a presumption of being ready for that next life and being sure that you’ll be reunited in the world to come based on faith7 – which in some senses is a not-knowing.
however, a good Calvinist epistemologist (yes, i’m side-eying Plantinga) might not say this, and may well lead us down a path of something like the presuppositional apologetics of cornelius van til. in these cases, the world of KNOWING seems to suggest that we need to accept that world’s God that makes it possible for an atheist like john to be so rationally minded in the beginning of the movie. john operates in the discursive frame of science and the academy and thus has to perform rationality to be credible. caleb is disappointed when he realizes (early in the movie) that john doesn’t believe in heaven. despite thinking that “shit just happens” and that “we can’t know for sure” (i.e., that heaven exists), at some point in the past john has accepted a presuppositional mindset, which he slowly regains as he sees the truths in the messages. he specifically notes that he lost a form of faith in knowing what was coming while in the throes of grief, which in turn led him to be more nomologically oriented. however, the list of numbers was an intervention that led him to reconsider his loss of faith, because despite how unlikely it might be to an extremely rational astrophysicist, he was called back to accept the presuppositions that inform all of his underlying complexities.
again, we need to remember this was most likely not intentionally a Calvinist apocalypse film. the statements of pearson and cage don’t jive with that. if anything, KNOWING indeed puts the onus on us to observe and dissect the discursive and epistemological frames we look through to square religion and the world. this is perhaps, indeed, why the movie is so baffling - that not even the angel/iens ever describe how or what ever directly to the audience. one cannot simply anticipate what will happen, and that in itself, leads to the revelatory experience of watching this film itself. without prior knowledge, without that grounding, you really have no fucking clue what you’re getting yourself into. with apologies to barthelme, this is the combinatorial agility of knowledge and belief, the exponential generation of meaning, once they’re allowed to go to bed together…5 — the liaison where we can experience the epistemic jouissance of KNOWING.
I recently read Tyson Yunkaporta's Right story, wrong story – his latest book after the one that grew a bunch of new synapses in my brain, Sand Talk.
It was a different experience. Perhaps it seemed less revelatory because I'd already read Sand Talk. Perhaps Yunkaporta just had less time to translate these ideas into something mainstream white Australians would understand. Perhaps the endless grind of trying to survive as an Indigenous person in a settler-colonial capitalist state made it harder to write. I'm not complaining – this is a great book and you should read it. But it's hard not to hope that when one reads an author's first book for a general audience and it utterly changed how one sees the world, that the next one will be just as exhilarating. It's hardly his fault that it didn't rewire my brain a second time.
The book covers a lot of ground, but the primary concept is that when telling a story (the best way to convey information) you can tell it in a way that is "right story", or you can tell it in a way that is "wrong story". The underlying message running through this is that how you convey information and tell stories is just as important as the "content" you are conveying.
In many ways this is not particularly New News. Any educator who has undergone any training in the last 30 years will know about "constructivism" and that the idea of education as simply passing knowledge to learners like one fills a jug with water is a completely inaccurate description of how learning actually works. But I think there are some additional, more subtle things here. It's not just that "active learning" is useful. How we explain things, who is acknowledged and who is silenced, what is noted and what is glossed over – all these things matter even if the subject matter seems very straightforward. Above all, Tyson Yunkaporta teaches me again and again the importance of Noticing. It's not a coincidence that I read Sand Talk in the second year of Melbourne's interminable Covid lockdowns, and that I started noticing things around my neighbourhood soon after – the flowering of different plant species, the changes in the bird populations from month to month, and even how vehicle traffic patterns had shifted. I'd never really paid much attention to any of that previously.
Speaking of noticing: something I noticed after finishing Right story, wrong story was that I suddenly had the urge to draw. It struck me because I had exactly the same compulsion after I read Sand Talk. Yunkaporta makes a carving in an object for each chapter in each of his books. This no doubt influenced me. But there must be more to it than that. Or rather, the way he writes, influenced by the way he carves patterns to record his ideas, influences me to think in patterns too. I don't really know what's going on here but it's definitely a thing. An important thing to understand here is that I am in no way "artistic". I don't habitually draw. Or at least I didn't until I started reading Yunkaporta's work. And I'm not sure that's really the point anyway. These are tools for working out what you're thinking, and recording it as a mnemonic device. I'm not sure about the mnemonic value of my drawings on digital paper, but I do find it helps me think things through and sometimes express things I can't quite articulate.
During lockdown I was surprised to find that the thing I most missed about the office was having a whiteboard to help me think things through. This is of course related, but I'm cautious about linking them too closely because ...well, I guess I don't like connecting what I think of as more wholesome brain-expanding processes with things that are just making me more effective as an Organisation Man. On this note, I recently discovered Abby Covert's Stuck? Diagrams help. via Tracy Forzaglia's MOD Librarian blog. I haven't read it yet but I'm thinking I'll probably splash out and get the ebook since diagramming things out seems to be so helpful for me.
Anyway, there's not some profound point to this post. I just decided to share some thoughts instead of being crippled by anxiety about whether my next blog post would be The Perfect Take. It never will be.
Below the fold is the text of a talk I gave to Berkeley's Information Systems Seminar exploring the history of attempts to build decentralized systems and why so many of them end up centralized.
As usual, you don't need to take notes. The text of my talk with links to the sources will go up at blog.dshr.org after this seminar.
This is a map of the location of tweets in Europe, colored by language. It vividly shows the contrast between a centralized society and more decentralized ones. I hope we can agree as to which one we'd prefer to live in.
The platonic ideal of a decentralized system has many advantages over a centralized one performing the same functions:
It has the economic advantage that it is hard to compare the total system cost with the benefits it provides because the cost is diffused across many independent budgets.
Why Not Decentralize?
But history shows that this platonic ideal is unachieveable because systems decentralization isn't binary and systems that aim to be at the decentralized end of the spectrum suffer four major problems:
Their advantages come with significant additional monetary and operational costs.
Their user experience is worse, being more complex, slower and less predictable.
They are in practice only as decentralized as the least decentralized layer in the stack.
They exhibit emergent behaviors that drive centralization.
In Gini Coefficients Of Cryptocurrencies I discussed various ways to measure decentralization.
Because decentralization applies at each layer of a system's stack, it is necessary to measure each of the subsystem individually. In 2017's Quantifying Decentralization Srinivasan and Lee identified a set of subsystems for public blockchains, and measured them using their proposed "Nakamoto Coefficient":
The Nakamoto coefficient is the number of units in a subsystem you need to control 51% of that subsystem.
Subsystem
Bitcoin
Ethereum
Mining
5
3
Client
1
1
Developer
5
2
Exchange
5
5
Node
3
4
Owner
456
72
Their table of the contemporary Nakamoto coefficients for Bitcoin and Ethereum makes the case that they were only minimally decentralized.
Blockchains exemplify a more rigorous way to assess decentralization; to ask whether a node can join the network autonomously, or whether it must obtain permission to join. If the system is "permissioned" it cannot be decentralized, it is centralized around the permission-granting authority. Truly decentralized systems must be "permissionless". My title is wrong; the talk is mostly about permissionless systems, not about the permssioned systems that claim to be decentralized but clearly aren't.
The world has been on a decades-long series of experiments trying to build successful decentralized systems marked almost entirely by failure. Forty years ago I played a small part in one of the first of these experiments. I was working at Carnegie-Mellon's Information Technology Center on the Andrew Project, one of three pioneering efforts in campus networking. The others were at Brown and MIT. It was generously funded by IBM, who were covering the campus with the massively over-engineered "IBM Cabling System". They really wanted these wires to carry IBM's Token Ring network supporting IBM's System Network Architecture (SNA). SNA was competing with the telco's X.25 and DARPA's IP stack for the future of networking, and it wasn't clear which would win. But the three campus projects were adamant that their networks would run IP, largely because it was non-proprietary and far less centralized.
It is true that TCP/IP now dominates the bottom layers of the stack, but the common complaint is that the systems layered on it are excessively centralized. DNS is centralized around the root servers and IANA's (Internet Assigned Numbers Authority) management of top-level DNS domains and the global IP and AS spaces. They are the Internet's permission-granting authority. To scale, they have delegated management of sub-spaces to others, but the fundamental centralization remains. The Web is so centralized around the tech giants that there is an entire decentralized web movement. E-mail is increasingly centralized around a few major providers making life for those like me who run their own e-mail servers more and more difficult.
The basis of TCP/IP is the end-to-end principle, that to the extent possible network nodes communicate directly with each other, not relying on functions in the infrastructure. So why the need for root servers and IANA? It is because nodes need some way to find each other, and the list of root servers' IP addresses provides a key into the hierarchical structure of DNS.
This illustrates the important point that a system is only as decentralized as the least decentralized layer in its stack.
LOCKSS
Fifteen years on from CMU when Vicky Reich and I started the LOCKSS program we needed a highly resilient system to preserve library materials, so the advantages of decentralization loomed large. In particular, we realized that:
A centralized system would provide an attractive target for litigation by the publisher oligopoly.
The paper library system already formed a decentralized, permissionless network.
Our idea was to build a permissionless peer-to-peer system in which libraries would hold copies of their subscription content and model the paper inter-library loan and copy system to repair any loss or damage to them. To detect loss or damage the nodes would vote on the hash of the content. We needed to defend against a "Sybil attack", in which a bad guy wishing to change some content would create enough nodes under his control to win the votes on it. Our initial attempts at designing a protocol were flawed, but we eventually won a "Best Paper" award at the 2003 SOSP conference for a protocol that used proof-of-work (PoW) as a way of making running a node expensive enough to deter Sybil attacks. An honest library need only run one node, the bad guy had to run more than the total of the honest libraries, so would pay many times the per-library cost.
Why LOCKSS Centralized
Software monoculture
Centralized development
Permissioning ensures funding
Big publishers hated decentralization
Although the LOCKSS technology was designed and implemented to be permissionless, there were a number of reasons why it turned out much less decentralized than we hoped:
Although we always paid a lot of attention to the security of LOCKSS boxes, we understood that a software monoculture was vulnerable to software supply chain attacks. So we designed a very simple protocol hoping that there would be multiple implementations. But it turned out that the things that a LOCKSS box needed to do other than handling the protocol were quite complex, so despite our best efforts we ended up with a software monoculture.
We hoped that by using the BSD open-source license we would create a diverse community of developers, but we over-estimated the expertise and the resources of the library community, so Stanford provided the overwhelming majority of the programming effort.
The program got started with small grants from Michael Lesk at NSF, then subsequently major grants from the NSF, Sun Microsystems and Don Waters at the Mellon Foundation. But Don was clear that grant funding could not provide the long-term sustainability needed for digital preservation. So he provided a matching grant to fund the transition to being funded by the system's users. This also transitioned the system to being permissioned, as a way to ensure the users paid.
Although many small and open-access publishers were happy to allow LOCKSS to preserve their content, the oligopoly publishers never were. Eventually they funded a completely closed network of a dozen huge systems at major libraries around the world called CLOCKSS. This is merely the biggest of a number of closed, private LOCKSS networks that were established to serve specific genres of content, such as government documents.
Gossip Protocols
If LOCKSS was to be permissionless there could be no equivalent of DNS, so how did a new node find other nodes to vote with?
A gossip protocol or epidemic protocol is a procedure or process of computer peer-to-peer communication that is based on the way epidemics spread. Some distributed systems use peer-to-peer gossip to ensure that data is disseminated to all members of a group. Some ad-hoc networks have no central registry and the only way to spread common data is to rely on each member to pass it along to their neighbors.
Suppose you have a decentralized network with thousands of nodes that can join and leave whenever they want, and you want to send a message to all the current nodes. This might be because they are maintaining a shared state, or to ask a question that a subset might be able to answer. You don't want to enumerate the nodes, because it would be costly in time and network traffic, and because the answer might be out-of-date by the time you got it. And even if you did sending messages individually to the thousands of nodes would be expensive. This is what IP multicast was for, but it doesn't work well in practice. So you build multicast on top of IP using a Gossip protocol.
Each node knows a few other nodes. The first time it receives a message it forwards it to them, along with the names of some of the nodes it knows. As the alternate name of "epidemic protocol" suggests, this is a remarkably effective mechanism. All that a new node needs in order to join is for the network to publish a few "bootstrap nodes", similar to the way an Internet node accesses DNS by having the set of root servers wired in. But this bootstrap mechanism is inevitably centralized.
The LOCKSS nodes used a gossip protocol to communicate, so in theory all a library needed to join in was to know another library running a node. In the world of academic libraries this didn't seem like a problem. It turned out that the bootstrap node all the libraries knew was Stanford, the place they got the software and the support. So just like DNS, the root identity was effectively wired-in.
Bitcoin
The network timestamps transactions by hashing them into an ongoing chain of hash-based proof-of-work, forming a record that cannot be changed without redoing the proof-of-work. The longest chain not only serves as proof of the sequence of events witnessed, but proof that it came from the largest pool of CPU power. As long as a majority of CPU power is controlled by nodes that are not cooperating to attack the network, they'll generate the longest chain and outpace attackers.
Fast forward another ten years and Satoshi Nakamoto published Bitcoin: A Peer-to-Peer Electronic Cash System, a ledger implemented as a chain of blocks containing transactions. Like LOCKSS, the system needed a Sybil-proof way to achieve consensus, in his case on the set of transactions in the next block to be added to the chain. Unlike LOCKSS, where nodes voted in single-phase elections, Nakamoto implemented a three-phase selection mechanism:
One node is selected from the network using Proof-of-Work. It is the first node to guess a nonce that made the hash of the block have the required number of leading zeros.
The selected node proposes the content of the next block via the gossip network.
The "longest chain rule", Nakamoto's most important contribution, ensures that the network achieves consensus on the block proposed by the selected node.
More than a decade earlier, W. Brian Arthur had published Increasing Returns and Path Dependence in the Economy explaining how the very strong economies of scale inherent to technology markets led to them being monopolized. Consider a new market opened up by a technological development. Several startups enter, for random reasons one gets bigger then the others, economies of scale make it more profitable and network effects make it more attractive to new customers, so this feedback loop drives it to out-compete the others.
The application to the Bitcoin network starts with this observation. The whole point of the Bitcoin protocol is to make running a miner, a node in the network, costly. The security of the system depends upon making an attack more costly to mount than it would gain. Miners need to defray the costs the system imposes in terms of power, hardware, bandwidth, staff and so on. Thus the protocol rewards miners with newly minted Bitcoin for winning the race for the next block.
Bitcoin Economics
Nakamoto's vision of the network was of many nodes of roughly equal power,"one CPU one vote". This has two scaling problems:
The target block time is 10 minutes, so in a network of 600 equal nodes the average time between rewards is 100 hours, or about 4 days. But in a network of 600,000 equal nodes it is about 4,000 days or about 11 years. In such a network the average node will never gain a reward before it is obsolete.
Moore's law means that over timescales of years the nodes are not equal, even if they are all CPUs. But shortly after Bitcoin launched, miners figured out that GPUs were much better mining rigs than CPUs, and later that mining ASICs were even better. Thus the miner's investment in hardware has only a short time to return a profit.
Mining Pools 02/27/23
The result was the formation of mining pools, allowing miners to contribute their power to a single huge node and trade their small chance of an infrequent large reward for a frequent flow of a small share of the node's rewards. But economies of scale applied even below the level of pools. A miner who could fill a warehouse with mining rigs or who was able to steal electricity would have much lower costs than a smaller miner. Thus they would not merely get more of the pool's block rewards, but they would keep more of them as profit. The success of this idea led to GHash.io's single node controlling the Bitcoin network with over 51% of the mining power. Most of it was from warehouses full of mining rigs.
The block rewards inflate the currency, currently by about $100M/day. This plus fees that can reach $23M/day, is the cost to run a system that currently processes 400K transactions/day, or over $250 per transaction plus up to $57 per transaction in fees. Lets talk about the excess costs of decentralization!
Like most permissionless networks, Bitcoin nodes communicate using a gossip protocol. So just like LOCKSS boxes, they need to know one or more bootstrap nodes in order to join the network, just like DNS and LOCKSS.
In Bitcoin Core, the canonical Bitcoin implementation, these bootstrap nodes are hard-coded as trusted DNS servers maintained by the core developers.
There are also fall-back nodes in case of DNS failure encoded in chainparamsseeds.h:
/**
* List of fixed seed nodes for the bitcoin network
* AUTOGENERATED by contrib/seeds/generate-seeds.py
*
* Each line contains a BIP155 serialized (networkID, addr, port) tuple.
*/
Fast forward another five years. Vicky Reich and I were driving North in my RX-7 for a long weekend at the Mendocino Hotel. On US101 before the driving got interesting on CA128 I was thinking about the recent period during which the GHash.io mining pool controlled 51% of Bitcoin's mining power.
I suddenly realized that this centralization wasn't something about Bitcoin, or LOCKSS for that matter. It was an inevitable result of economic forces generic to all peer-to-peer systems. So I spent much of the weekend sitting in one of the hotel's luxurious houses writing Economies of Scale in Peer-to-Peer Networks.
My insight was that the need to make an attack expensive wasn't something about Bitcoin, any permissionless peer-to-peer network would have the same need. In each case the lack of a root of trust meant that security was linear in cost, not exponential as with, for example, systems using encryption based upon a certificate authority. Thus any successful decentralized peer-to-peer network would need to reimburse nodes for the costs they incurred. How can the nodes' costs be reimbursed?:
There is no central authority capable of collecting funds from users and distributing them to the miners in proportion to these efforts. Thus miners' reimbursement must be generated organically by the blockchain itself; a permissionless blockchain needs a cryptocurrency to be secure.
And thus any successful permissionless network would be subject to the centralizing force of economies of scale.
There have been many attempts to create alternatives to Bitcoin, but of the current total "market cap" of around $2.5T Bitcoin and Ethereum represent $1.75T or 70%. The top 10 "decentralized" coins represent $1.92T, or 77%, so you can see that the coin market is dominated by just two coins. Adding in the top 5 coins that don't even claim to be decentralized gets you to 87% of the total "market cap".
The fact that the coins ranked 3, 6 and 7 by "market cap" don't even claim to be decentralized shows that decentralization is irrelevant to cryptocurrency users. Numbers 3 and 7 are stablecoins with a combined "market cap" of $134B. The largest stablecoin that claims to be decentralized is DAI, ranked at 24 with a "market cap" of $5B. Launching a new currency by claiming better, more decentralized technology than Bitcoin or Ethereum is pointless, as examples such as Chia, now ranked #182, demonstrate. Users care about liquidity, not about technology.
Ethereum made a praiseworthy effort to reduce their environmental impact by switching from Proof-of-Work to Proof-of-Stake and, in an impressive feat of software engineering, managed a smooth transition. The transition to Proof-of-Stake did in fact greatly reduce the Ethereum network's power consumption. Some fraction of the previous mining power was redirected to mine other Proof-of-Work coins, so the effect on the power consumption of cryptocurrencies as a whole was less significant. But it didn't reduce centralization, as the contrast between the before and after pie-charts shows.
Ethereum Validators
Time in proof-of-stake Ethereum is divided into slots (12 seconds) and epochs (32 slots). One validator is randomly selected to be a block proposer in every slot. This validator is responsible for creating a new block and sending it out to other nodes on the network. Also in every slot, a committee of validators is randomly chosen, whose votes are used to determine the validity of the block being proposed. Dividing the validator set up into committees is important for keeping the network load manageable. Committees divide up the validator set so that every active validator attests in every epoch, but not in every slot.
Ethereum's consensus mechanism is vastly more complex than Bitcoin's, but it shares the same three-phase structure. In essence, this is how it works. To take part, a node must stake, or escrow, more than a minimum amount of the cryptocurrency,then:
The one node proposes the content of the next block.
The "committee" of other validator nodes vote to approve the block, leading to consensus.
Just as Bitcoin and LOCKSS share Proof-of-Work, Ethereum's Proof-of-Stake and LOCKSS share another technique, voting by a random subset of the electorate. In LOCKSS the goal of this randomization was not just "keeping the network load manageable", but also making life hard for the bad guy. To avoid detection, the bad guy needed to vote only in polls where he controlled a large majority of the random subset of the nodes. This was something it was hard for him to know. I'm not clear whether the same thing applies to Ethereum.
Like Bitcoin, the nodes taking part in consensus gain a block reward currently running at $2.75M/day and fees running about $26M/day. This is the cost to run a distributed computer 1/5000 as powerful as a Raspberry Pi.
Validator Centralization
The prospect of a US approval of Ether exchange-traded funds threatens to exacerbate the Ethereum ecosystem’s concentration problem by keeping staked tokens in the hands of a few providers, S&P Global warns.
...
Coinbase Global Inc. is already the second-largest validator ... controlling about 14% of staked Ether. The top provider, Lido, controls 31.7% of the staked tokens,
...
US institutions issuing Ether-staking ETFs are more likely to pick an institutional digital asset custodian, such as Coinbase, while side-stepping decentralized protocols such as Lido. That represents a growing concentration risk if Coinbase takes a significant share of staked ether, the analysts wrote.
Coinbase is already a staking provider for three of the four largest ether-staking ETFs outside the US, they wrote. For the recently approved Bitcoin ETF, Coinbase was the most popular choice of crypto custodian by issuers. The company safekeeps about 90% of the roughly $37 billion in Bitcoin ETF assets, chief executive officer Brian Armstrong said
A system in which those with lots of money make lots more money but those with a little money pay those with a lot, and which has large economies of scale, might be expected to suffer centralization. As the pie-chart shows, this is what happened. In particular, exchanges hold large amounts of Ethereum on behalf of their customers, and they naturally stake it to earn income. The top two validators, the Lido pool and the Coinbase exchange, have 46.1% of the stake, and the top five have 56.7%.
In its solicitations for public comments on the proposed spot Ether ETFs, the SEC asked, “Are there particular features related to ether and its ecosystem, including its proof of stake consensus mechanism and concentration of control or influence by a few individuals or entities, that raise unique concerns about ether’s susceptibility to fraud and manipulation?”
A bug in Ethereum's Nethermind client software – used by validators of the blockchain to interact with the network – knocked out a chunk of the chain's key operators on Sunday.
...
Nethermind powers around 8% of the validators that operate Ethereum, and this weekend's bug was critical enough to pull those validators offline. ... the Nethermind incident followed a similar outage earlier in January that impacted Besu, the client software behind around 5% of Ethereum's validators.
...
Around 85% of Ethereum's validators are currently powered by Geth, and the recent outages to smaller execution clients have renewed concerns that Geth's dominant market position could pose grave consequences if there were ever issues with its programming.
...
Cygaar cited data from the website execution-diversity.info noting that popular crypto exchanges like Coinbase, Binance and Kraken all rely on Geth to run their staking services. "Users who are staked in protocols that run Geth would lose their ETH" in the event of a critical issue," Cygaar wrote.
The fundamental problem is that most layers in the software stack are highly concentrated, starting with the three operating systems. Network effects and economies of sclae apply at every layer. Remember "no-one ever gets fired for buying IBM"? At the Ethereum layer, it is "no-one ever gets fired using Geth" because, if there was ever a big problem with Geth, the blame would be so widely shared.
The Decentralized Web
One mystery was why venture capitalists like Andreesen Horwitz, normally so insistent on establishing wildly profitable monopolies, were so keen on the idea of a Web 3 implemented as "decentralized apps" (dApps) running on blockchains like Ethereum. Moxie Marlinspike revealed the reason:
companies have emerged that sell API access to an ethereum node they run as a service, along with providing analytics, enhanced APIs they’ve built on top of the default ethereum APIs, and access to historical transactions. Which sounds… familiar. At this point, there are basically two companies. Almost all dApps use either Infura or Alchemy in order to interact with the blockchain. In fact, even when you connect a wallet like MetaMask to a dApp, and the dApp interacts with the blockchain via your wallet, MetaMask is just making calls to Infura!
Providing a viable user experience when interacting with blockchains is a market with economies of scale and network effects, so it has centralized.
It Isn't About The Technology
What is the centralization that decentralized Web advocates are reacting against? Clearly, it is the domination of the Web by the FANG (Facebook, Amazon, Netflix, Google) and a few other large companies such as the cable oligopoly.
These companies came to dominate the Web for economic not technological reasons. The Web, like other technology markets, has very large increasing returns to scale (network effects, duh!). These companies build centralized systems using technology that isn't inherently centralized but which has increasing returns to scale. It is the increasing returns to scale that drive the centralization.
The four FANG companies last year had a combined free cash flow of $159.7B. I know of no decentralized Web effort that has a viable business model. This isn't surprising, since they are focused on developing technology not a business model. This means they pose no threat to the FANG. Consider that, despite Elon Musk's attempts to make it unusable and the availability of federated alternatives such as Mastodon, Twitter retains the vast bulk of its user base. But as I explained in Competition-proofing, if they ever did pose a threat, in the current state of anti-trust the FANGs would just buy them. In 2018 I wrote in It Isn't About The Technology:
If a decentralized Web doesn't achieve mass participation, nothing has really changed. If it does, someone will have figured out how to leverage antitrust to enable it. And someone will have designed a technical infrastructure that fit with and built on that discovery, not a technical infrastructure designed to scratch the itches of technologists.
Unless decentralized technologies specifically address the issue of how to avoid increasing returns to scale they will not, of themselves, fix this economic problem. Their increasing returns to scale will drive layering centralized businesses on top of decentralized infrastructure, replicating the problem we face now, just on different infrastructure.
The only way that has worked in practice to avoid increasing returns to scale is not to reimburse nodes for their costs, but to require them to be run as a public service. The example we have of avoiding centralization in this way is Bram Cohen's BitTorrent, it is the exception that proves the rule. The network doesn't reward nodes for hosting content, but many sites find it a convenient way to distribute content. The network doesn't need consensus, thus despite being permissionless it isn't vulnerable to a Sybil attack. Users have to trust that the tracker correctly describes its content, so there are other possible attacks. But if we look at the content layer, it is still centralized. The vast majority of the content is at a few large sites like The Pirate Bay.
Every widely used blockchain has a privileged set of entities that can modify the semantics of the blockchain to potentially change past transactions.
The "privileged set of entities" must at least include the developers and maintainers of the software, because:
The challenge with using a blockchain is that one has to either (a) accept its immutability and trust that its programmers did not introduce a bug, or (b) permit upgradeable contracts or off-chain code that share the same trust issues as a centralized approach.
A dense, possibly non-scale-free, subnetwork of Bitcoin nodes appears to be largely responsible for reaching consensus and communicating with miners—the vast majority of nodes do not meaningfully contribute to the health of the network.
Trail of Bits found remarkable vulnerabilities to internal or external supply chain attacks because:
The Ethereum ecosystem has a significant amount of code reuse: 90% of recently deployed Ethereum smart contracts are at least 56% similar to each other.
The risk isn't confined to individual ecosystems, it is generic to the entire cryptosphere because, as the chart shows, the code reuse spans across blockchains to such an extent that Ethereum's Geth shares 90% of its code with Bitcoin Core.
I mentioned Moxie Marlinspike's My first impressions of web3 showing that dApps all used Infura or Alchemy. Many of them implement "decentralized finance" (DeFi), and much research shows this layer has centralized.
Prof. Hilary Allen's DeFi: Shadow Banking 2.0? concludes:
TL;DR: DeFi is neither decentralized, nor very good finance, so regulators should have no qualms about clamping down on it to protect the stability of our financial system and broader economy.
While the main vision of DeFi’s proponents is intermediation without centralised entities, we argue that some form of centralisation is inevitable. As such, there is a “decentralisation illusion”. First and foremost, centralised governance is needed to take strategic and operational decisions. In addition, some features in DeFi, notably the consensus mechanism, favour a concentration of power.
Based on the [Herfindahl-Hirschman Index], the most competition exists between decentralized finance exchanges, with the top four venues holding about 54% of total market share. Other categories including decentralized derivatives exchanges, DeFi lenders, and liquid staking, are much less competitive. For example, the top four liquid staking projects hold about 90% of total market share in that category,
Based on data on 180 days of revenue of DeFI projects from Shen's article, I compiled this table, showing that the top project, Lido, had 55% of the revenue, the top two had 2/3, and the top four projects had 78%. This is clearly a highly concentrated market, typical of cryptocurrency markets in general.
The alternative to decentralization that is currently popular, especially in social media, is federation. Instead of forming a single system, federation allows many centralized subsystems to interoperate. Examples include BlueSky, Threads and Mastodon. Federation does offer significant advantages, including the opportunity for competition in the policies offered, and the ability for users to migrate to services they find more congenial.
How attractive are these advantages? The first bar chart shows worldwide web traffic to social media sites. Every single one of these sites is centralized, even the barely visible ones like Nextdoor. Note that Meta owns 3 of the top 4, with about 5 times the traffic of Twitter.
The second bar chart shows monthly active users (MAUs) on mobile devices in the US. This one does have two barely visible systems that are intended eventually to be federated, Threads and Bluesky. Despite the opportunity provided by Elon Musk, the federated competitors have had minimal impact:
That leaves Mastodon with a total of 1.8 million monthly active users at present, an increase of 5% month-over-month and 10,000 servers, up 12%
In terms of monthly active users, Twitter claims 528M, Threads claims 130M, Bluesky claims 5.2M and Mastodon claims 1.8M. Note that the only federate-able one with significant market share is owned by the company that owns 3 of the top 4 centralized systems. Facebook claims 3,000M MAU, Instagram claims 2,000M MAU, and WhatsApp claims 2,000 MAU. Thus Threads is about 3% of Facebook alone, so not significant in Meta's overall business. It may be early days yet, but federated social media have a long way to go before they have significant market share.
Summary
Radia Perlman's answer to the question of what exactly you get in return for the decentralization provided by the enormous resource cost of blockchain technologies is:
a ledger agreed upon by consensus of thousands of anonymous entities, none of which can be held responsible or be shut down by some malevolent government
In the case of blockchain protocols, the mathematical and economic reasoning behind the safety of the consensus often relies crucially on the uncoordinated choice model, or the assumption that the game consists of many small actors that make decisions independently. If any one actor gets more than 1/3 of the mining power in a proof of work system, they can gain outsized profits by selfish-mining. However, can we really say that the uncoordinated choice model is realistic when 90% of the Bitcoin network’s mining power is well-coordinated enough to show up together at the same conference?
As we have seen, in practice it just isn't true that "the game consists of many small actors that make decisions independently" or "thousands of anonymous entities". Even if you could prove that there were "thousands of anonymous entities", there would be no way to prove that they were making "decisions independently". One of the advantages of decentralization that Buterin claims is:
it is much harder for participants in decentralized systems to collude to act in ways that benefit them at the expense of other participants, whereas the leaderships of corporations and governments collude in ways that benefit themselves but harm less well-coordinated citizens, customers, employees and the general public all the time.
But this is only the case if in fact "the game consists of many small actors that make decisions independently" and they are "anonymous entities" so that it is hard for the leader of a conspiracy to find conspirators to recruit via off-chain communication. Alas, the last part isn't true for blockchains like Ethereum that support "smart contracts", as Philip Daian et al's On-Chain Vote Buying and the Rise of Dark DAOs shows that "smart contracts" also provide for untraceable on-chain collusion in which the parties are mutually pseudonymous.
Questions
If we want the advantages of permissionless, decentralized systems in the real world, we need answers to these questions:
What is a viable business model for participation that has decreasing returns to scale?
How can Sybil attacks be prevented other than by imposing massive costs?
How can collusion between supposedly independent nodes be prevented?
What software development and deployment model prevents a monoculture emerging?
Does federation provide the upsides of decentralization without the downsides?
As announced in January, this year the Open Knowledge Foundation (OKFN) team is working to develop a stable version of the Open Data Editor (ODE) application. Thanks to financial support from the Patrick J. McGovern Foundation, we will be able to create a no-code tool for data manipulation and publishing that is accessible to everyone, unlocking the power of data for key groups including scientists, journalists and data activists.
[Disclaimer: Open Data Editor is currently available for download and testing in beta. We are working on a stable version. Updates will be announced throughout the year. Learn more here.]
Since the beginning of the year, we’ve been working on building the ODE team and conducting the first phase of user research. We have interviewed 10 people so far, covering different user profiles such as journalists, people working in NGOs and the private sector, and data practitioners in general.
The Open Data Editor is built on top of Frictionless Data specifications and software, and is an example of a simple, open-by-design alternative to the complex software offered by the Big Tech industry. Developing this type of technology is part of our current strategic focus on promoting and supporting the development of open digital public infrastructure that is accessible to all.
As part of this, we want to open up this process in a series of blogs, sharing with the community and those interested in the world of open data how each stage of the creation of this software is developing.
What have we learned so far?
Put people first: organisations need to spend more time on user research. Organisations can lose money and spend unnecessary time on things that may not be as useful as they think if they don’t reach out to their community and try to understand their problems before building solutions. This may sound obvious, but it happens all the time.
Spend more time thinking about the problem you are trying to solve. Whenever you want to improve a tool, you may be tempted to jump in and try to fix it from a technical point of view. This can create a bigger problem. It’s important to take a step back, learn everything you can about the tool, and talk to potential users to understand if what the technology is trying to solve is a real problem for them.
Build diverse and interdisciplinary teams. The current OKFN team working on ODE includes three software developers, a product owner and a project manager. We all have different expertise and backgrounds, which is key to being able to put ourselves in the shoes of our potential users. Most importantly, we are all data practitioners ourselves!
Do not reinvent the wheel: check out the resources your community has already made available. This is also a good way to reuse resources that your community has opened up, so that you spend less time on key parts of your work. For example, during our research process we used the amazing Discovery Kit created by the Open Contracting Partnership. Although the toolkit was originally developed to help teams build tools and software using open contracting data, we followed the advice and used some elements, such as their user personas, to adapt it for our specific work.
Share and iterate your ideas with people outside your organisation. Getting external insights is a very good practice for those building open source products. “Sharing is caring” is good for you and your products
Initial findings
After the first round of user interviews, here are the first conclusions on the difficulties and current state of the art of tabular open data according to data practitioners.
Same old problems. Data practitioners still spend a lot of time exploring and cleaning data. Analysis is only a small part.
The struggle with PDFs continues. Some respondents explained how they have to manually copy and paste data or use technologies such as Tabula to extract tables from PDFs.
Preferred tools for exploring and cleaning data: Spreadsheet tools like Google Sheets, Open Office and Excel.
Favourite features to start exploring the data: Pivot tables and filters.
Generative AI “not for data analysis”. Data practitioners, especially journalists, are reluctant to use AI for data analysis or to draw conclusions from the data they’re working with. They don’t want to share their datasets without knowing how they’re being used (privacy concerns), and because it’s impossible to reconstruct what the technology is doing to achieve specific results.
You can also find more details in the following presentation.
If you want to get more closely involved with the development of the Open Data Editor application, you can express your interest in joining one of the testing sessions by filling this form.
DETROITography organized an Open Data Day hybrid event on 7 March 2024 at the Purdy/Kresge Library on the Wayne State University (WSU) campus in Detroit, Michigan, USA. The presentation focused on neighborhood data discovery through the relaunched CKAN data portal and catalog called DetroitData, crowdsourced input on community boundaries via Detroit-Neighborhoods.com, and the launch of an open data platform to track the city of Detroit’s progress on the SDGs using OpenSDG.
I led the presentation first focusing on the relaunch of DetroitData as the open data catalog for the city. A few city and regional entities have their own open data portals, but nonprofits and community organizations don’t have a place to share and contribute to the city’s data narrative. I also highlighted how DetroitData can serve as an essential resource for journalists who utilize FOIA or “freedom of information act” requests to open up data from local government entities. DetroitData currently compiles over 1,000 datasets shared by more than 50 local organizations.
The next presentation featured the Detroit-Neighborhoods.com tool to collect and analyze community input on neighborhood boundaries. Detroit has a long history of defining neighborhoods without much community engagement or feedback. The tool specifically tallies a submitted response related to how the city government defines a neighborhood area as well as what the degree of agreement there is among those submitting. Alex shared that the hope for the site is that community groups can use it as a data-driven tool to better advocate for their neighborhood boundaries.
Finally, the session ended with a discussion around the Sustainable Development Goals (SDGs) in Detroit and how well they are tracked at the city level. The OpenSDG platform applied to Detroit will slowly be adding new datasets that highlight where the city is at in relation to the global goals. As the only UNESCO City of Design in the USA, Detroit must make concerted efforts to achieve the SDGs for every community and neighborhood. The participants were very excited and engaged with the presentation with detailed questions on community involvement and ensuring clear background information gets shared about datasets. A cohort of WSU Libraries staff were on hand and shared their passion for metadata. Future collaborations are likely as the School of Information Science works to train new librarians on digital tools and metadata maintenance.
About Open Data Day
Open Data Day (ODD) is an annual celebration of open data all over the world. Groups from many countries create local events on the day where they will use open data in their communities.
As a way to increase the representation of different cultures, since 2023 we offer the opportunity for organisations to host an Open Data Day event on the best date within a one-week period. In 2024, a total of 287 events happened all over the world between March 2nd-8th, in 60+ countries using 15 different languages.
All outputs are open for everyone to use and re-use.
In 2024, Open Data Day was also a part of the HOT OpenSummit ’23-24 initiative, a creative programme of global event collaborations that leverages experience, passion and connection to drive strong networks and collective action across the humanitarian open mapping movement
For more information, you can reach out to the Open Knowledge Foundation team by emailing opendataday@okfn.org. You can also join the Open Data Day Google Group to ask for advice or share tips and get connected with others.
We encourage proposals from members and non-members; regulars and newcomers; digital library practitioners from all sectors (higher education, museums and cultural heritage, public libraries, archives, etc.) and those in adjacent fields such as institutional research and educational technology; and students, early- and mid-career professionals and senior staff alike. We especially welcome proposals from individuals who bring diverse professional and life experiences to the conference, including those from underrepresented or historically excluded racial, ethnic, or religious backgrounds, immigrants, veterans, those with disabilities, and people of all sexual orientations or gender identities.
The submission deadline is Wednesday, May 15, at 11:59pm Eastern Time.
Curious about submitting a proposal but not sure where to start?
Join the next CFP Office Hours on Tuesday, April 30 at 1pm ET USA to learn more about the virtual DLF Forum and session types for our virtual event. Register in advance.
If you have any questions, please write to us at forum@diglib.org. We’re looking forward to seeing you online this fall.
In Brief: Although the academic libraries profession recognizes that retention is a complex and important issue, especially for advancing diversity, equity and inclusion (DEI) initiatives and supporting BIPOC librarians, the library literature largely avoids defining or providing a measurement for retention at all. In this paper we propose an original nuanced definition of retention. We draw from existing research on workplace dynamics and library culture and our qualitative exploration of academic librarians who have left jobs before they intended. Our research investigated what it was like for them to stay at those jobs after they realized they didn’t want to stay long-term. We argue that structural aspects of the academic library profession (such as emotional investment in the profession, geographic challenges, and role specialization) can lead to librarians staying with organizations longer than they would otherwise, and that this involuntary staying is not functional retention. We explore the distinction between involuntarily staying and voluntarily staying at an organization, as well as the coping strategies library employees may engage in when they involuntarily stay. Finally, we make the argument that functional retention is a relationship between the organization and the individual employee in which both sides are positively contributing to the workplace culture.
The authors applied the language of the American Psychological Association’s Journal Article Reporting Standards for Race, Ethnicity, and Culture (JARS–REC) (American Psychological Association, 2023). We are writing from a North American context and acknowledge the ways that race is defined differently based upon national and cultural contexts. The language and understanding of race are not universal and terms and language usage evolve as norms and practices evolve. We chose to use the terms “Black, Indigenous, and People of Color (BIPOC)” and “underrepresented racial and ethnic groups.” Our participants self-identified their race and ethnicity but in an attempt to maintain strict confidentiality, we made the choice to identify the race of the participants using the terminology of BIPOC and only identified the race of the interviewee when making explicit points about race, ethnicity, and culture.
Introduction
In this paper, we propose a nuanced definition of retention of librarians that distinguishes between functional and dysfunctional retention. We do this by integrating existing research on workplace dynamics and library culture with a qualitative exploration of academic librarians who have left jobs before they intended and what it was like for them to stay at those jobs after they realized they didn’t want to stay long-term. As a result of this exploration, we argue that structural aspects of the academic library profession (such as emotional investment in the profession, geographic challenges, and role specialization) can lead to librarians staying with organizations longer than they would otherwise and that this “involuntary staying” is not functional retention.
The Association of College and Research Libraries (ACRL) and the Association of Research Libraries (ARL) have been interested in strengthening recruitment and retention of academic librarians from underrepresented racial and ethnic groups since at least the early 1990s, and in the early 2000s named this issue a priority for the library profession (Neely & Peterson, 2007). Institutions and professional organizations responded by increasing the number of scholarships, training programs, and postgraduate residency programs aimed at supporting new graduates in finding entry-level positions (Boyd et al., 2017). However, for all of the discourse on “recruitment and retention,” a majority of the emphasis has been on recruitment, which is easier to quantify, with little study of how retention functions in an academic library environment (Bugg, 2016). The profession has focused on recruiting more librarians from underrepresented racial and ethnic groups, but we have not prioritized supporting them to stay(Hathcock, 2015).As a result, the numbers of Black, Indigenous, and people of color (BIPOC) librarians has stagnated or in some cases, actually decreased (ALA Office of Research and Statistics, 2017; American Library Association, 2012; Barrientos et al., 2019). Recruitment and retention are both critical to diversity, equity, and inclusion efforts in academic libraries, and failing to improve retention has and will continue to derail these initiatives (Hodge et al., 2021).
As we looked deeper into the literature on retention in academic libraries, we recognized that the concepts of recruitment and retention have become intertwined, with recruitment as the primary focus of the literature, leaving retention insufficiently studied and defined. Research that addresses retention tends to focus on proposed strategies, such as stay interviews (structured interviews aimed at strengthening employee and employer relationships) and mentorship programs (SHRM, n.d.-a). At the same time, there is no agreed-upon definition of retention that would allow us to assess these strategies. ACRL recently published a toolkit for library worker retention that defines retention as “the ability of an organization to reduce turnover among employees and keep employees for as long as possible” (Nevius, 2023). While this definition is a good starting point for discussion, it is vague and immediately raises questions, namely whether keeping employees “for as long as possible” is truly an appropriate goal for academic libraries.
As academic libraries attempt to define and assess retention, we should recognize that involuntary staying can be just as negative an outcome for the individual and the organization as leaving, setting the stage for legacy toxicity, which persists even through leadership changes (Kendrick, 2023). At the same time, trying to understand these dynamics will help us design policies and programs to encourage work environments that are conducive to individual and organizational goals, and propagate structural solutions across the profession. We argue that functional retention is a positive, engaged relationship between the employee and the organization, where both are contributing to a workplace that is positive, safe, and harmonious.
Toward A Definition of Retention
Most studies on retention within academic library literature reflect “retention management,” defined as strategic initiatives aimed at reducing turnover within institutions, where turnover is defined as employees leaving the organization (SHRM, n.d.-b, 2023). These studies touch on many types of initiatives, including strategies to retain librarians in their current positions (Musser, 2001; Strothmann & Ohler, 2011) and factors that encourage retention such as onboarding (Chapman, 2009; Hall-Ellis, 2014). More specifically, researchers have examined mentoring of librarians from underrepresented racial and ethnic groups (Olivas & Ma, 2009); professional development for librarians from underrepresented racial and ethnic groups (Acree et al., 2001); and inquiry into why librarians leave positions (Heady et al., 2020).
There is clear recognition in the library literature that retention is important and complex, yet we were unable to find a solid definition or agreed-upon understanding of what it means to successfully retain someone prior to ACRL’s definition, which only came online in mid-2023 (Nevius, 2023).Some researchers have acknowledged the complications inherent in retention efforts. Both Bugg (2016) and Musser (2001) state that retention requires long term communication and commitment from multiple actors across the academic libraries profession, not just by individual institutions. Consequently, the profession tends to focus its efforts on recruitment and programs like mentorship to attempt to retain employees and does not address bigger and more complex issues such as workplace culture and environment, job satisfaction, bullying, toxicity, racism, and low morale (Alajmi & Alasousi, 2018; Dewitt-Miller & Crawford, 2020; Freedman & Vreven, 2016; Kendrick, 2017; Kendrick & Damasco, 2019).
Within human resources management (HRM) literature, the definition of retention varies depending on the field in question. In a 2015 scoping review, Al-Emadi and colleagues acknowledge the variety of ways retention is defined within HRM and present a working definition of retention as “initiatives taken by management to keep employees from leaving the organization, such as rewarding employees for performing their jobs effectively, ensuring harmonious working relations between employees and managers, and maintaining a safe, healthy work environment” (Al-Emadi et al., 2015, p. 8). This definition also reflects “retention management” as described above, but is helpful in that it explains retention as an actionthat an organization takes (rather than a passive state that employees are in) and underscores the importance of the workplace environment and relationships between employees and managers. At the same time, this definition limits potential assessment for academic libraries.
Why Do Librarians Stay?
There are many reasons academic librarians remain with organizations where they are generally satisfied and feel that their personal and professional needs are being met; these reasons have been explored in the Library and Information Science (LIS) literature (Alajmi & Alasousi, 2018; Kawasaki, 2006), as well as the HRM literature (SHRM, 2023). However, we were interested in reasons why academic librarians may stay in organizations when they are not happy.
The research describing the academic librarian job market generally concludes that academic library jobs are difficult to obtain. Tewell points out that historically, the librarianship job narrative has moved between a model of “job scarcity” and a “recruitment crisis” but ultimately, entry level jobs are considered highly competitive (2012, p. 408). Other researchers have examined the perceived necessity of additional educational requirements to be considered competitive for an academic librarian position (Ferguson, 2016), the precariousness of academic librarian positions (Henninger et al., 2020), and the experiences of part time librarians looking for full time employment (Wilkinson, 2015). Ultimately, the research demonstrates that there is a perception of job scarcity within the academic libraries profession, meaning that transitioning to a new job is not as straightforward as in some other fields and may be a significant reason some librarians stay at their current jobs.
Many librarians are bound geographically to their libraries and workplaces (Kendrick, 2021; Ortega, 2017). Library workers who have familial and/or care-taking obligations cannot easily move to a new location for a new position, and may be subject to a limited job market in their current location. Many positions in academic libraries are highly specialized and draw from a national candidate pool, so even if there are several academic libraries available, there is no guarantee that an appropriate position will become available or that any individual can count on being hired. Likewise, career advancement can often require changing organizations or moving away from a home location, especially given that many academic libraries have flat organizational structures and very small staffs (Ortega, 2017). Academic librarians are also subject to the “two-body problem,” where dual-career couples must navigate job markets in a way that accommodates both careers (Fisher, 2015).
Petersen (2023) reinforces this quandary, writing about career paths that force workers to leave their bases of support to maintain their specialized livelihoods and the resulting challenges workers face in creating new support networks as adults. She describes this situation as a type of “job lock,” a term often applied to situations where employees are stuck at jobs because of non-portable benefits (like health insurance in the U.S.) but has also been used to describe other situations where employees feel unable to leave jobs (Huysse-Gaytandjieva et al., 2013, p. 588). Ritter (2023) also discusses the costs of transient careers often required of higher education workers and coins the term “academic stranger,” referring to a mobile-by-default mentality that encourages workers to accept work conditions that are socially destabilizing. Pho and Fife (2023) point to a similar narrative in academic libraries that mobility and the resulting emotional connections and disconnections are expected as librarians move from place to place to support their professional needs. Consequently, it’s natural for academic librarians to build their lives around their jobs and the people at those jobs, which can make it hard to leave an unsatisfying position.
Spencer (2022) describes this phenomenon as professional “hypermobility” or “nomadism” and emphasizes that it has positive and negative aspects, but needs to be more transparent to those considering entering the academic libraries field. Petersen argues that in fields “where jobs are scarce, [geographic] mobility is a privilege” that creates inequality in the job market and reinforces the idea that holding any job is lucky: “you take what you get and the expected posture is gratitude” (2023).
Another reason why librarians might be hesitant to leave is because they feel deeply emotionally connected to their job. Ettarh’s work on “vocational awe” in the library profession, described as “the set of ideas, values, and assumptions librarians have about themselves and the profession that result in beliefs that libraries as institutions are inherently good and sacred, and therefore beyond critique,” sheds light on why librarians may stay in jobs that exploit them (2018). Similarly, Petersen (2022) describes library jobs as “passion jobs,” which she identifies as “prime for exploitation,” because they are often feminized and devalued. She describes how many nonprofit organizations, including libraries, work with as few staff as possible and don’t always fill vacant positions; as a result, individuals may feel guilty for leaving because of likely consequences for their coworkers and/or patrons.
What Pushes Librarians to Leave?
Over the past decade, there has been a fair amount of focus on determining why academic librarians leave their organizations; specifically related to bullying, toxicity, and low morale in academic libraries (for example, Freedman & Vreven, 2016; Heady et al., 2020; Kendrick, 2017, 2021; Ortega, 2017). Although most of these studies assess librarians after they’ve left a job, this body of research offers insight into why a librarian might move toward involuntary staying.
Kendrick discusses the concept of a “trigger event,” which is described as “an unexpected negative event ora relationship that developed in an unexpected and negative manner” (Kendrick, 2017, p. 851). Participants in her study “perceived trigger events as the beginning of a long-term abuse cycle” (p. 853). Most employees don’t leave their job immediately after a trigger event occurs, if ever, but are forced to reevaluate their understanding of the organization and their role there. It is this mindset shift that we will describe as moving toward involuntary staying.
Ortega’s (2017) definition of toxic leadership, characterized by “egregious actions” and “causing considerable and long-lasting damage,” can help us understand traits of toxic workplaces where employees no longer want to stay (p. 35). Ortega’s and Kendrick’s (2017) studies both support the idea that toxicity becomes an ingrained part of the organizational culture. When employees leave toxic library workplaces, they are not leaving because of one bad day or even one bad leader, but because of a pattern and culture of toxicity. Research from Heady, et al. (2020) reinforces that when academic librarians leave, they are “not fleeing their positions, they are fleeing work environments they feel are toxic” (p. 591) and that morale, culture, library administration, and direct supervisors were the top factors in their decisions to leave (p. 585–586).
Understanding Turnover
As we attempt to better understand retention, it’s helpful to begin with a framework for understanding turnover, commonly defined in the HRM field as the “movement of employees out of the organization” (SHRM, n.d.-b). There are different types of turnover, as shown in Figure 1.
Allen divides turnover into involuntary(i.e. an employee is fired or otherwise dismissed at the organization’s discretion) and voluntary (i.e. an employee leaves the organization because they want to). Even considering only voluntary turnover, there are many varied reasons that would require different kinds of attention from an organization. If turnover is measured simply as the total number of workers who left the organization in a set period of time (SHRM, n.d.-b), it’s easy to see why an organization would struggle to understand if they had a retention problem or not, or what they might be able to do about it. Therefore, “reducing turnover” is too simplistic a goal (Nevius, 2023).
The opposite of turnover is staying in an organization, which we argue is not the same thing as true retention. Staying doesn’t automatically mean that an employee is content or that retention initiatives are working. Turnover may reasonably be defined as failed retention, but retention should not be simply the absence of turnover.
Understanding Retention through Staying
Based on Allen’s 2008 classification of turnover, we can also classify different categories of staying, defined as the opposite of turnover, or an employee who has not left the organization. We use the terms voluntary and involuntaryto describe staying, similar to Allen’s approach, but in the case of staying, it’s important to note that voluntary staying and involuntary staying are mindsets and, unlike turnover, are not simply classifications of an event. Voluntary staying is a state of mind where an employee is generally satisfied and engaged to the point that they are not looking for other positions or needing coping strategies to survive their current work life. Generally, employees join organizations (i.e. begin new positions) voluntarily staying.
Figure 2: Voluntary and Involuntary Staying
When an employee becomes dissatisfied, disengaged, and starts to use coping strategies to survive their work life, they have moved from voluntarily staying to involuntarily staying. This does not mean that they will necessarily begin looking for another job right away, or ever. While the employee may be experiencing job-lock at the same time (when external factors such as non-portable health benefits prevent someone from leaving their job), involuntary staying describes their mindset and feelings about the job. In our study, we interviewed librarians who had experienced this involuntarily staying state at a previous job.
Our qualitative research described in this paper sought to explore the moments or events that caused librarians to leave jobs before they intended and their experiences once they decided to leave. Given how difficult it is to switch jobs in our field, what was it that tipped the scales for them, making staying untenable? What were their experiences and what could we learn from them about how to define and improve retention of librarians in the future? Through this exploration, we learned about these original questions, but also about the interplay between library culture, management, leaving and staying, and turnover and retention.
Methods
The qualitative data was gathered through 10 semi-structured interviews of academic librarians who left jobs sooner than they’d planned, for job-related reasons as opposed to personal reasons, such as moving to be closer to family. Using an interview guide (See Appendix A), we sought to learn about the interviewees’ experiences as they realized that they could no longer stay at their job and what happened before and after that realization. While we suspected that these experiences would be a little different for everyone, we hoped to expand our general understanding of times when employees were not retained by their organization (that is, when retention failed) and the effects on the individual and the organization in the time period between an employee realizing they wanted to leave and actually leaving.
The interviews, lasting approximately one hour each, were conducted between January 2021–June 2021. Participants were drawn from a pool of 57 responses to a screening survey seeking participants who had left a job before they had planned to. From our pool of respondents, we selected seven participants who identified as BIPOC (a sample that included participants identifying as non-Black POC, but none who identified as indigenous) and three participants who identified as white, using a random number generator to select participants from each strata (see Appendix B). We intentionally oversampled BIPOC librarians, to center their voices as we explored themes related to race and white supremacy culture, and acknowledging that people from historically marginalized groups are often positioned to have unique insight into dominant cultures. Our screening survey did not specify whether respondents should be managers or non-managers themselves, and we learned during our interviews that both were represented in our sample.
Our overall sample size of 10 interviews was relatively small. This was partially for practical reasons, but also because our research team agreed after our 10 interviews that we’d reached sufficient saturation; that is, we believed additional interviews would not yield new themes (Strauss & Corbin, 2014, p. 148).
Interviews were conducted via Zoom by two researchers and audio-recorded with participants’ permission. Interview audio was transcribed using Descript and copyedited and de-identified by the researchers. Consistent with our consent agreement, participants are identified in our writing only by an assigned code number (e.g. “Interviewee 7”), their self-identified gender pronouns, and whether they self-identified as BIPOC or white.
Each transcription was coded by at least two researchers using grounded theory methodology, per Strauss and Corbin (2014), meaning that a codebook was developed during analysis based on recurring themes across interviews. In addition to exploring our research questions, a secondary goal was to provide space for participants to share their experiences, which many had never shared before, and to have these experiences heard and validated as legitimate (see Cunningham et al., 2023).
Results
The majority of our interviewees started out their positions in a state of voluntary staying: they expressed positive feelings about their jobs at the start and described minimal or no red flags during interviews. They discussed things like specific job duties or opportunities that appealed to them, positive feelings about compensation, and a feeling that they could “have a career there” (Interviewee 2).
Over time, interviewees either experienced “trigger events” (“an unexpected negative event ora relationship that developed in an unexpected and negative manner,” as described by Kendrick, 2017, p. 851) or general increasing awareness of things being “off,” specifically related to organizational culture. These trigger events and off feelings led our interviewees to move from a state of voluntarily staying to involuntarily staying.
One example of this was Interviewee 9, who was happily in her job for four years when a radical restructuring of the library departments occurred with no warning. Interviewee 9 noted that after this restructuring occurred, she and her colleagues began engaging in “checked out” behavior.
Oh yeah. We all checked out for sure…Well, one thing you saw was people left immediately at five [and] people didn’t come in early. There was not as much engagement just on the social level. Like before this[–]and this is gonna sound like some kind of weird, perfect land[–but] we went to eat lunch together all at the same time in the lunchroom. And people had a good social relationship. After [the restructuring,] people would avoid each other.
A few months after the initial restructuring, Interviewee 9 had a defining moment in which she received explicit discouragement from her new supervisor:
I was a high achiever. I seemed to be moving forward. And my boss turned to me, my new boss, in a meeting with other people there and said, “there are people in this organization that think that they are moving forward and they will never move forward under me,” while staring at me very directly. So, I mean, I didn’t have a career there anymore, so.
This was the final straw for Interviewee 9 and she began looking for a new job immediately. This example highlights that “involuntarily staying” is more of a frame of mind than a specific period of time and also that an employee can be involuntarily staying while not actively looking for another job. In the case of Interviewee 9, she went from happy in her job to one of many “checked out” people and finally to actively looking for a new job once it became clear that she was on her new supervisor’s “shit list.”
Interviewee 5 presents a contrasting example in which the Interviewee stayed in his position for a longer period of time:
I had trigger events, yes. Now having said that, it still took me five years to leave that job. And there’s a lot of factors in that.
Interviewee 5 described two trigger events in which he clashed with library leadership and was written up. He was at the job for a total of five years, but notes that his job search was “four years long,” indicating a very long period of involuntarily staying. Ultimately, he left without a job offer when he recognized that his health was suffering:
When I finally left that institution, I left without having a job offer at all. So it was important that I needed to get out of there and it was tak[ing] tolls on my health and everything else. My coping mechanisms had went [sic] from healthy to unhealthy, so it was time to go.
A third example is from Interviewee 1 who was on a three-year contract with her institution and noted, “I can live through anything for three years.” However, this interviewee experienced a trigger event where her boss changed a positive work review to a negative one after she refused to provide him with personal information. She realized that she could not stay, but was also conflicted about leaving colleagues and patrons:
I just felt like that just killed it. Like there was no resurrecting that relationship. After that, I worked out the rest of that contract because […] you know, I did like the students, we were very close to several of them and my colleagues and I didn’t want to leave them in the lurch because [if] I left, someone else would pick up the slack and there wasn’t enough of them to go around in the first place. So I was very mindful of that, but that was the event where I’m like, you know, can this marriage be saved? No, that was it.
As explained earlier, “involuntarily staying” is a mindset rather than a specific period of time. In our interviews, the time period between the interviewee realizing they could no longer stay in a job and them actually leaving ranged from nearly immediately to years. Their sense of immediacy also ranged from relatively casual to dire.
What all our interviewees had in common is that they moved from voluntarily staying to involuntarily staying and engaged in a range of coping mechanisms to survive once they realized that staying was untenable and until they were able to leave. This is congruent with Kendrick’s stages of low morale when onset of coping strategies eventually follows trigger events and exposure to workplace abuse or neglect (Kendrick, 2021, p. 12).
Borrowing again from Allen (2008), we use the terms “functional” and “dysfunctional” to classify the coping mechanisms described by our interview participants. One important point of departure is that Allen’s terminology views outcomes from the organization’s perspective, while our study is interested in outcomes for the employee and the organization. Therefore, we classify coping strategies as functional, or, congruous with the health of the individual and the organization, or dysfunctional, or unhealthy for the individual and/or the organization (see Figure 3).
Figure 3: Functional and Dysfunctional Coping Strategies
Some examples of functional coping strategies recounted by interviewees:
Regularly validating yourself and your feelings:
[I’d say:] ‘You’re not crazy. You’re not imagining this. They’re treating you as poorly as you think they are.’ And I think a lot of times some of these things flourish because people are made to feel like they’re exaggerating or overly sensitive, and they don’t have the support system to know that what they’re feeling is entirely valid. (Interviewee 1)
Seeking perspective from outside the organization:
I would say you know, find your mentor, who are [sic] hopefully outside of your institution, because you know, if you’re in a toxic workplace and your mentor is inside, if they’ve been there for a while, it can look like it’s normal when it’s really not normal. So you need someone on the outside to help you to kind of navigate bad experience[s]. (Interviewee 10)
Regularly reminding oneself that “it’s not personal”:
I [would tell someone in a similar situation] to remember that it is not personal… And the reason that it’s important people know that is, one, it feels a lot worse if it feels personal. But the other thing is, that part of that feeling of personalness makes it harder for you to decide ‘screw this, I’m going.’ You know, you recognize that you are a cog in a capitalist machine. You can take your little cog-self somewhere else where they will pay you more. (Interviewee 9)
Prioritizing physical and mental health.
Finding healthy ways to release anger and frustration.
Finding validation and support from ally colleagues, especially among BIPOC colleagues.
Setting and practicing strong boundaries around work and work interactions.
Examples of dysfunctional coping strategies described by interviewees:
Warning new folks not to try too hard and to “stay in their lanes.” This was practiced by both interviewees and their colleagues and was described by multiple interviewees as having both functional and dysfunctional aspects.
[I was told:] If you just do what everybody tells you to do and stay away from the riff-raff…and stay below the fray you’ll do well [and] move up here. (Interviewee 5)
[The advice I was given was:] ‘Stay under the radar. Don’t try to do too much.’ (Interviewee 3)
Participating in a culture of resentment and grudge-holding.
[There were] existing tensions and grudges and resentment, that’s been building over years and it’s created such a hostile environment where you can’t necessarily stay neutral. (Interviewee 3)
Disengaging with meaningful work or “checking out”.
I just put the rest on autopilot, right. I stopped sharing ideas…I devoted myself to my job search. (Interviewee 6)
Creating or reinforcing organizational silos.
It’s also important to note that the line between functional and dysfunctional coping strategies is thin and often not very meaningful without context. A coping mechanism that is functional in one scenario may be dysfunctional in another. Likewise, a coping mechanism that is functional from an individual’s perspective may sometimes be counterproductive from an organizational perspective, or vice versa. Often interviewees described using functional and dysfunctional coping strategies simultaneously. Additionally, we are not arguing that all employees who engage in harmful behaviors are doing so because they have moved into a state of involuntary staying.
Discussion
The library literature has established that toxic leadership and organizational culture can cause or contribute to individuals leaving their organizations. Our study suggests that organizational culture also influences whether an employee is voluntarily or involuntarily staying at the organization, and whether their coping strategies are functional or dysfunctional. We can also see, just as all employees participate in organizational culture in some way, that employees’ dysfunctional coping strategies can feed into and reinforce toxic culture, creating a feedback loop.
Further, academic librarianship as a profession has structural features, described earlier, that can prolong an employee’s period of involuntary staying at an organization and therefore exacerbate the situation for all involved. Our findings about dysfunctional coping mechanisms complicate the ACRL Toolkit’s definition of retention that includes a goal of keeping employees “for as long as possible” (Nevius, 2023). In some scenarios, keeping employees is not in the best interest of the individual or the organization.
It’s important to note, though, that this does not mean that leaders of an organization should force an employee to leave. While managers and leaders should proactively address any disruptive behaviors from employees (many of which we’ve described here as dysfunctional coping strategies), the onus is on the organization to confront toxic culture and not punish individual employees for the ways they try to survive toxic work environments. It should also be recognized that disruptive behavior lies on a continuum; there are certain actors in libraries who would label calling out racist or homophobic practices as disruptive. This can be particularly fraught for employees who are expected to be “library nice,” a framework describing a highly “racialized and gendered form of workplace oppression,” where being perceived as nice is “more important than [their] knowledge, skill, or effectiveness” (Kendrick, 2021, p. 18).
Instead, we propose that retention in academic libraries is about building and maintaining a relationship between the organization and its employees that supports employees tovoluntarily stay. Retention studies and strategies should take into account the different varieties of turnover and staying to help organizations honestly assess how they are building cultures that encourage employees to voluntarily stay, with the active acknowledgement that those from underrepresented racial and ethnic groups are often structurally situated to be the most negatively impacted by toxic library culture. Initiatives to improve retention should center employees’ well-being and agency, recognizing that employees and organizations both have much to gain from improving functional retention, but responsibility for bringing retention forward as an organizational focus area ultimately lies with library leaders.
Functional retention requires good leadership, but is also dependent on building and solidifying a culture of accountability, transparency, open discussion, anti-racism, vulnerability, safety, and courtesy that is resilient to legacy toxicity and where most or all librarians are staying voluntarily. While leaders can set the stage for this kind of culture, all employees have an influence on the culture and responsibility for its success. To reiterate, functional retention is a positive relationship between the employee and the organization, with both sides contributing to a workplace that is positive, emotionally and physically safe, and harmonious.
Recommendations for organizations:
Engage in a regular cycle of assessment.
Be proactive about retention. Recognize that functional retention is built through consistent, deliberate actions.
Seek to understand turnover at your organization. This is important even in job markets where employers have the upper hand over job-seekers (as is true for many academic librarian positions).
Seek to understand retention at your organization. When measuring retention, aim to learn whether your employees are staying voluntarily or involuntarily.
Strategies such as “stay interviews” (a corollary to exit interviews) and “intent to stay” instruments (developed in the field of nursing) may be useful, but it isn’t clear how often either have been deployed in academic libraries thus far and how effective they will be in this environment (Kosmoski & Calkin, 1986; Nevius, 2023).
Recognize that not all employees may feel safe answering truthfully.
Ask employees what could improve their experience and listen to their answers.
Use their answers to design or transform your retention strategies.
Reflections & Future Directions
We were able to learn a lot about these issues from our literature review, interviews, and analysis, and we hope that our research opens many doors for future study.
Our small sample size, though appropriate for qualitative inquiry, means that we can’t say anything meaningful about differences between demographic groups (e.g. whether BIPOC librarians might experience longer periods of involuntary staying), the potential impacts of other intersecting identities beyond race, or whether our findings are truly generalizable. It would be desirable in the future to have quantitative evidence and a representative sample. Additionally, future study of involuntary staying and its implications for functional retention should also include experiences of librarians who are involuntarily staying and have not left their organizations.
We continue to be curious about many of the threads unearthed in our data: for example, the role of training for managers, the responsibilities of professional organizations, and the roles of human resources professionals or ombudspeople.
Finally, the COVID-19 pandemic was responsible for igniting new questions across all sectors about employees’ relationships to work and their employers. While we believe that there are structural aspects of higher education and academic libraries that distinguish our profession, it will be essential to link studies of library workplaces more closely with research and thinkers from many fields outside our own. For example, how did academic libraries’ responses to the pandemic change the way librarians felt about their organizations and their roles, and how might this impact whether they are voluntarily or involuntarily staying? How does the framing of “quiet quitting,” or doing the minimum requirements for a job, impact involuntarily staying? How should changing societal attitudes about mutual aid and collective care factor into our approaches to measuring functional retention? These are important questions that we hope will be incorporated into future explorations.
Acknowledgments
We would like to express our thanks to Jessica Schomberg, Brittany Paloma Fiedler, and Kaetrena Davis Kendrick for their time and flexibility in guiding us through the publishing process. We are genuinely grateful for their constructive and insightful feedback and suggestions at every stage.
This article represents several years of workshopping and sharpening our ideas through conversations with each other, colleagues, and with audience members from presentations at several conferences; we appreciate all of these contributions.
We would also like to recognize the grant from the Friends of Boatwright Library at the University of Richmond that allowed us to compensate our interviewees for their time.
Finally, we are sincerely grateful to our interviewees, who each generously shared their stories, even when they were painful, so that others may feel less alone and in service of building a better profession for all of us.
Appendix A: Semi-structured interview guide
However you answer, we aren’t here to judge you. We are coming from a place of research and empowerment. Your experiences are valid and are being heard.
Before we begin, we want to review a piece of the Informed Consent Statement you signed — as stated there, public reports of our research findings will invoke participants by a pseudonym and job title only, and that you will be given the chance to designate your own job title. This could be more specific (like “social sciences liaison librarian”), less specific (“liaison librarian”), or very general (“academic librarian”) depending on your preference. You are also welcome to choose your own pseudonym if you’d like.
What appealed to you about Job 1?
What was your interview process like for Job 1? Did you feel any red flags? In retrospect?
If someone was working at this organization, what would you like them to know?
How was the library structured administratively? Where did you fit in the hierarchical structure of the library? Who did you directly report to? Did you have any direct reports?
What aspects did you like about your daily job duties?
What aspects did you dislike about your daily job?
Did you have colleagues you trusted?
How were they able to navigate their jobs?
Did you have support?
How did that support manifest?
Kendrick (2017) defines trigger events as “an unexpected negative event ora relationship that developed in an unexpected and negative manner.” Was there a trigger event for you?
How did you begin your new job search?
Did you feel that the environment was personal, or was it part of a larger cultural problem?
Did HR ever seem like an option?
Were attempts made to retain you*? Is there anything that could have been done to retain you? How would you have liked to see this event handled?
How could this have been made right?/How would you have preferred supervisors/admin to have addressed the issue?
In retrospect, would you have done anything differently?
Do you think that the problems were specific to that library, or library culture in general?
What would you tell someone else who is in a similar situation?
What would you tell someone who is interested in applying to your (old) position?
*Note: We used the term “retain” in our interview guide referring to a situation when an organization incentivizes an employee to stay after they’ve indicated that they’re planning to leave (for example, with a salary counter-offer). We acknowledge that this usage of the term and concept is different from how we came to understand retention over the course of this project.
Appendix B
Interviewee #
Race/Ethnicity and Pronouns (self-identified by interviewee)
1
BIPOC (she/her)
2
White (she/her)
3
BIPOC (he/him)
4
BIPOC (she/her)
5
BIPOC (he/him)
6
BIPOC (she/her)
7
BIPOC (she/her)
8
White (she/her)
9
White (she/her)
10
BIPOC (she/her)
Table 1. Summary of Interview Participants
References
Acree, E. K., Epps, S. K., Gilmore, Y., & Henriques, C. (2001). Using professional development as a retention tool for underrepresented academic librarians. Journal of Library Administration, 33(1–2), 45–61. https://doi.org/10.1300/J111v33n01_05
Alajmi, B., & Alasousi, H. (2018). Understanding and motivating academic library employees: Theoretical implications. Library Management, 40(3/4), 203–214. https://doi.org/10.1108/LM-10-2017-0111
Al-Emadi, A. A. Q., Schwabenland, C., & Wei, Q. (2015). The vital role of employee retention in human resource management: A literature review. IUP Journal of Organizational Behavior, 14(3), 7–32.
Barrientos, Q., Kendrick, K. D., & Flash, K. (2019). Roundtable discussion: Institutional vagaries of retention and Recruitment and the actuality of emotional labor in diversity initiatives. ACRL 2019, Cleveland, OH. https://usclmedford.omeka.net/items/show/51
Boyd, A., Blue, Y., & Im, S. (2017). Evaluation of academic library residency programs in the United States for librarians of color. College & Research Libraries, 78(4), 472–511. https://doi.org/10.5860/crl.78.4.472
Bugg, K. (2016). The perceptions of people color in academic libraries concerning the relationship between retention and advancement as middle managers. Journal of Library Administration, 56(4), 428–443.
Chapman, C. (2009). Retention begins before day one: Orientation and socialization in libraries. New Library World, 110(3/4), 122–135. https://doi.org/10.1108/03074800910941329
Dewitt-Miller, E., & Crawford, L. (2020, March 10). Tackling toxicity: Predicting, surviving, & preventing toxic workplaces [Poster]. Electronic Resources & Libraries Conference, March 8-11, 2020. Austin, Texas, United States. https://digital.library.unt.edu/ark:/67531/metadc1637689/
Ferguson, J. (2016). Additional degree required? Advanced subject knowledge and academic librarianship. Portal: Libraries and the Academy, 16(4), 721–736. https://doi.org/10.1353/pla.2016.0049
Fisher, C. D. (2015). Embracing the “two-body problem”: The case of partnered academics. Industrial and Organizational Psychology, 8(1), 13–18. https://doi.org/10.1017/iop.2014.4
Freedman, S., & Vreven, D. (2016). Workplace incivility and bullying in the library: Perception or reality? College & Research Libraries, 77(6), 727–748. https://doi.org/10.5860/crl.77.6.727
Hall-Ellis, S. D. (2014). Onboarding to improve library retention and productivity. The Bottom Line, 27(4), 138–141.
Heady, C., Fyn, A. F., Kaufman, A. F., Hosier, A., & Weber, M. (2020). Contributory factors to academic librarian turnover: A mixed-methods study. Journal of Library Administration, 60(6), 579–599. https://doi.org/10.1080/01930826.2020.1748425
Henninger, E., Brons, A., Riley, C., & Yin, C. (2020). Factors associated with the prevalence of precarious positions in Canadian libraries: Statistical analysis of a national job board. Evidence Based Library and Information Practice, 15(3), 78–102. https://doi.org/10.18438/eblip29783
Huysse-Gaytandjieva, A., Groot, W., & Pavlova, M. (2013). A new perspective on job lock. Social Indicators Research, 112(3), 587–610. https://doi.org/10.1007/s11205-012-0072-2
Kawasaki, J. L. (2006). Retention–-After hiring then what? In Recruiting, Training, and Retention of Science and Technology Librarians. Routledge.
Kendrick, K. D. (2017). The low morale experience of academic librarians: A phenomenological study. Journal of Library Administration, 57(8), 846–878. https://doi.org/10.1080/01930826.2017.1368325
Kendrick, K. D. (2021). Leaving the low-morale experience: A qualitative study. Alki: The Washington Library Association Journal, 37(2), 9–24.
Kendrick, K. D. (2023). The cornered office: A qualitative study of low-morale experiences in formal library leaders. Journal of Library Administration, 63(3), 307–338. https://doi.org/10.1080/01930826.2023.2177924
Kendrick, K. D., & Damasco, I. T. (2019). Low morale in ethnic and racial minority academic librarians: An experiential study. Library Trends, 68(2), 174–212. https://doi.org/10.1353/lib.2019.0036
Kosmoski, K. A., & Calkin, J. D. (1986). Critical care nurses’ intent to stay in their positions. Research in Nursing & Health, 9(1), 3–10. https://doi.org/10.1002/nur.4770090103
Musser, L. R. (2001). Effective retention strategies for diverse employees. Journal of Library Administration, 33(1–2), 63. https://doi.org/10.1300/J111v33n01_06
Neely, T. Y., & Peterson, L. (2007). Achieving racial and ethnic diversity among academic and research librarians: The recruitment, retention, and advancement of librarians of color—A white paper. College & Research Libraries News, 68(9), 562–565. https://doi.org/10.5860/crln.68.9.7869
Olivas, A., & Ma, R. (2009). Increasing retention in minority librarians through mentoring. Electronic Journal of Academic and Special Librarianship, 10(3).
Ortega, A. (2017). Academic libraries and toxic leadership. Chandos Publishing.
Pho, A., & Fife, D. (2023). The cost of librarianship: Relocating for work and finding community. College & Research Libraries News, 84(6), 191–194. https://doi.org/10.5860/crln.84.6.191
Strothmann, M., & Ohler, L. A. (2011). Retaining academic librarians: By chance or by design? Library Management, 32(3), 191–208. https://doi.org/10.1108/01435121111112907
Tewell, E. C. (2012). Employment opportunities for new academic librarians: Assessing the availability of entry level jobs. Portal: Libraries and the Academy, 12(4), 407–423. https://doi.org/10.1353/pla.2012.0040
Wilkinson, Z. T. (2015). A human resources dilemma? Emergent themes in the experiences of part-time librarians. Journal of Library Administration, 55(5), 343–361. https://doi.org/10.1080/01930826.2015.1047253
In the Library with the Lead Pipe welcomes substantive discussion about the content of published articles. This includes critical feedback. However, comments that are personal attacks or harassment will not be posted. All comments are moderated before posting to ensure that they comply with the Code of Conduct. The editorial board reviews comments on an infrequent schedule (and sometimes WordPress eats comments), so if you have submitted a comment that abides by the Code of Conduct and it hasn’t been posted within a week, please email us at itlwtlp at gmail dot com!
Below the fold is the story of how I got a full-time Internet connection at my apartment 32 years ago next month, and the incredible success of my first ISP.
The reason I'm now able to tell this story is that Tom Jennings, the moving spirit behind the ISP has twoposts describing the history of The Little Garden, which was the name the ISP had adopted (from a Chinese restaurant in Palo Alto) when I joined it in May 1993. Tom's perspective from the ISP's point of view contrasts with my perspective — that of a fairly early customer enhanced by information via e-mail from John Gilmore and Tim Pozar, who were both involved far earlier than I.
Jennings starts his story:
Once upon a time, three little businesses wanted a connection to the ARPAnet/internet. The year was 1990 or 1991. John Gilmore, John Romke[y], and Trusted Information Systems (TIS) split the $15K or so it took to get a leased-line and 3COM Brouters to Alternet, with what today you'd call fractional T1. An additional 56K leased line and Brouter brought the 'net up to Gilmore's house, Toad Hall, in San Francisco.
The three little businesses were Cygnus Support (John Gilmore), Epilogue Technology (John Romkey) and Trusted Information Systems (Steve Crocker). AlterNet was run by Rick Adams, whom Wikipedia justly describes as an "Internet pioneer". He founded UUNET Technologies:
In the mid-1990s, UUNET was the fastest-growing ISP, outpacing MCI and Sprint. At its peak, Internet traffic was briefly doubling every few months, which translates to 10x growth each year.
John Gilmore, a truly wonderful person, had many friends. So what happened was:
As time went on, friends of theirs wanted in on this rare and exciting 'net connection, resulting in Tim Pozar putting an old PC running Phil Karn's KA9Q/NOS program, an amateur radio router capable of TCP/IP, onto Toad Hall's ethernet. Tim installed a pair of modems, then dialed in once and stayed connected 24 hrs/day (Pacific Bell never said you couldn't do that...)
Once Tim showed that it was possible, this idea took off:
Eventually the NOS box was full, and more friends wanted in, but everyone was too busy to deal with the hassle.
Somehow, in September 1992, Pozar and Gilmore and I worked out a deal where, I would maintain the thing, collect money to build more NOS boxes and contribute to the monthly Alternet bill, install more people, and get (1) a free connection to the internet and (2) a slice off the top after it exceeded N connections.
By that December, there were enough connections in place that I was pocketing $420/month. By March 1993 there were 11 modem-connected members (as we fancied ourselves).
In 1989 Gilmore had co-founded Cygnus Support, whose tagline was "Making free software affordable". TLG got started in August 1990 with the three businesses' nodes on a 56K leased line. One was at Cygnus first office in an apartment complex on University Avenue in Palo Alto. Gilmore and other Cygnus employees had apartments there, so they used 10BASE2 coaxial cable Ethernet to distribute the Internet around the complex. Gilmore notes that they used "nonstandard thin 50-ohm coax in the expansion joints across the driveways when needed". Pozar notes that they paved over the coax!
Gilmore was paying more than $300/mo for modem phone lines supporting the Alt Usenet groups, and realized that for less than that he could have a 56K line from Cygnus to his basement in SF. That led to Pozar and Rich Morin's Canta Forda Computer installing the old PC and becoming the first to use the permanent local call idea.
I knew Gilmore from the early days of Sun Microsystems (he was employee #5), so I first found out about the Point of Presence (PoP) in his basement in late 1992 and really wanted to join in. Alas, there was a snag — the reason the idea worked was that local phone calls were free. From my home in Palo Alto to Toad Hall was a toll call, making it impossibly expensive. But in May 1993 I found out about the PoP on University, 8 blocks from my apartment.
I purchased:
A phone line from Pacific Bell at the PoP.
A second phone line at my apartment.
A pair of Zyxel 9.6Kb modems, one for the PoP and one for my apartment.
If memory serves, it cost $250 installation fee and $70/month, and Tom Jennings helped me plug in one of the modems at the University PoP. I already had two SparcStations, a SparcStation SLC with an external SCSI hard disk I bought on Sun's employee purchase program, and a SparcStation 1+, the prizes Steve Kleiman and I won in an internal "Vision Quest" at Sun. My apartment was open-plan and the 1+'s fans were too noisy to let me sleep, but the SLC was fanless and could be on-line continuously. The SLC, the hard disk and the modem sat on a conveniently large window ledge. There was a wired Ethernet connection from the window ledge to the desk. When I say "wired" I mean that it ran on the apartments internal phone wires, but the distance was short enough that it worked.
This setup was remarkably reliable. If the call dropped, the SunOS SLIP software automatically re-dialled it. I have no memory of problems with it; I think the only times it was down were when I upgraded the modems as faster ones became available, or when I put the whole system on an Uninterruptible Power Supply. It may have been then that I noticed it had been up over 500 days. I didn't really need the UPS, Palo Alto's municipal utilities are also very reliable.
As I recall it ran happily until I passed the apartment on to my step-daughter's family in summer 2000. Seven years of impeccable service. By that time I was working on the LOCKSS program at Stanford, and we had DSL service from Stanford IT. So I went from an ISP with great tech support to an ISP with great support. Then as I relate in ISP Monopolies in September 2001 Palo Alto's Fiber-to-the-Home trial went live and I had 10Mbit bi-directional fiber with great support from Palo Alto Utilities. Since the trial ended our ISP has been Sonic, first over 3/1Mbit DSL and now over gigabit fiber. So we are really used to having great support from our ISP.
Luckily we were bought by Best Internet Communications, Mountain View; they had money, marketing, and a non-burned-out management; we had a solid locked-in customer base and positive cash flow.
Best turned out to be a pretty good ISP too.
Jennings' explanations for TLG's success are interesting. First, technical competence:
Edgar Nielsen almost single-handedly built the technical infrastructure that TLGnet ran on. He designed much of the network and routing structure, all of the security (with some help from Stu Grossman), wrote a complete, queryable, shared and remotely-accessible database (included every single modem, router, wire, cable, customer, IP (domain names and IP address allocations), and logical link) in standard and portable tools, installed equipment, built and maintained our unix boxes, put SNMP on every single node (hundreds) and automated the entire ISP technical infrastructure from one end to the other. I doubt many small to mid-size ISPs today have the things Edgar wrote by 1995.
Another thing of crucial importance to me, and to Deke, Edgar and a lesser extent Gilmore, was hiring from our local communities; we hired principled people, punk and queer writers and organizers, and trained and paid them -- pay in scale with effort. Total staff turn-over in three years was probably 20; peak staff was 12. Some 10 of them started out at $8.00/hr, unskilled, ended up with $30,000 salary a year later [1994-1996], and stayed in the industry (at prevailing pay). (And we provided health insurance too. Deke being damned Wobbly may have had some small effect.)
...
we treated our staff well, gave them credit for work done, paid them actual money, gave raises and bonuses (upon sale of the business, even some fired employees got small bonus checks). TLGnet wouldn't have existed without its talented staff!
TLGnet exercises no control whatsoever over the content of the information passing through TLGnet. You are free to communicate commercial, noncommercial, personal, questionable, obnoxious, annoying, or any other kind of information, misinformation, or disinformation through our service. You are fully responsible for the privacy of, content of, and liability for your own communications.
Concentrate on bulk, fulltime internet access (leased-line and Frame Relay)
Keep prices low by providing connectivity only
Unrestricted use of TLG connectivity
Encourage resale and vertical-market services
Full, up-front disclosure of all pricing
No lock-in contracts
Unbundle installation costs and eliminate padding
Full technical disclosure of technical information
Essentially, other ISPs restricted use and resale of their connections, in a sort of zero-sum approach. By concentrating on bulk connectivity we at once created a market for our customers to provide the vertical services we didn't want or couldn't afford to provide, and built a hard-to-beat solid rep that for a long while locked out direct competitors to our core business; having our prices online and breaking down the leased-line costs and equipment gave us a major one-up economically, technically, and in credible reputation over nearly all other ISPs, big or small.
Some thought us insane; but in fact our customers didn't "compete" with us, they provided vertical services we couldn't or wouldn't (I guess we did have a business plan). And in fact we set further standards of behavior and policies that other ISPs, including MCI and SprintLink, were obliged to match. Though some, like Alternet and PSI, never did; they skimmed the high-end deep-pockets customers, and we got all the new growth.
Gilmore writes:
I would add to the "Busines Model" discussion, that communication costs per-bit dropped dramatically with volume. When you upgraded from 56k bit/sec leased lines to T1 (1,500k bit/sec), you got 24x the bandwidth but it only cost about 4x as much. An upgrade to T3 (45 megabit) provided 30x the bandwidth of a T1, and didn't cost anything near to 30x as much. So, as your traffic volume grew because you were adding more and more customers, the cost of your basic connection to the rest of the Internet got significantly cheaper (per bit). That economy of scale meant that ISPs who grew could keep affording to upgrade their backbones to handle the traffic growth. Every ISP knew, or figured out, this economics, and they all depended on it. Remember, this was back when there were 2000 ISP's in the US, mostly local ones. (About 30 of them were getting their Internet service from TLG when we sold it to Best.)
There is a fascinating October 29 1996 interview entitled Tim Pozar and Brewster Kahle CHM Interview by Marc Weber. The first part of the interview is all about TLG. In it Brewster Kahle sums up the story (I cleaned up his stream of conciousness a bit):
it took six months of a full-time person to get us on the DARPA net in 1985 ... but The Little Garden basically made it so that any old person [could connect] and more than that not just themselves but ... enabling other people to create their own ISPs and I don't know there are 400 ISPs now in the Bay Area in large part because of The Little Garden.
On March 2 to 4 2024, UPI Youthmappers successfully held the Open Data Day 2024 event, with the theme “Bus-friendly: mapping participation guiding blocks & halt for equality of public transportation users and engaging disabled voices”. This event lasted for 3 days with a total of 15 participants.
On the first day, UPI Youth Mappers succeeded in making the event a success with a series of activities carried out in the Reka Working Space. First, there was a Hands-on activity using Open Street Maps and Wikipedia. Then presented experienced speakers who shared information regarding “Public Awareness of the Importance of Access for Disabled People in Public Transportation”. Apart from that, UPI Youth Mappers also invited friends who had disabilities, so the sharing session felt more interesting. On the first day, there were also prizes for active participants, but apparently, all participants actively took part in the event on the first day.
On the second day, it was the day when the participants and committee collected data at every stop in Corridor 4, namely Dago-Leuwi Panjang Terminal, Bandung. This data collection activity was very exciting and all participants succeeded in collecting data to later provide information regarding accessibility for disabled users who use bus transportation, namely Trans Metro Pasundan. The second day’s activities start at 9 am until 2 pm.
Then the final day was held on March 4 2024 online via Zoom Meeting. The event on the third day was data input into Open Street Maps (OSM) obtained during the field survey. The data entered into OSM is data related to disabled users who use the Pasundan Trans Metro Bus, supplemented with photos of the condition of all bus stops. Each participant inputs data independently in their respective OSM accounts, and is directed by UPI Youth Mappers. The third day of activities closed with the announcement of the most active participants and the distribution of prizes. And with a group photo session.
Our Open Data Day 2024 event was expected to open up knowledge related to our awareness that people with disabilities need to pay attention when using public transportation, namely buses and the availability of good and disability-friendly facilities. By obtaining a number of data and information on OSM, we hope that it will be useful. Thank you for participating in making the 2024 Open Data Day event a success by UPI Youth Mappers!
About Open Data Day
Open Data Day (ODD) is an annual celebration of open data all over the world. Groups from many countries create local events on the day where they will use open data in their communities.
As a way to increase the representation of different cultures, since 2023 we offer the opportunity for organisations to host an Open Data Day event on the best date within a one-week period. In 2024, a total of 287 events happened all over the world between March 2nd-8th, in 60+ countries using 15 different languages.
All outputs are open for everyone to use and re-use.
In 2024, Open Data Day was also a part of the HOT OpenSummit ’23-24 initiative, a creative programme of global event collaborations that leverages experience, passion and connection to drive strong networks and collective action across the humanitarian open mapping movement
For more information, you can reach out to the Open Knowledge Foundation team by emailing opendataday@okfn.org. You can also join the Open Data Day Google Group to ask for advice or share tips and get connected with others.
I didn’t read Nicholas Carr’s The
Shallows when it came out in 2011. I was working as a software
engineer at the Library of Congress helping put historical newspapers
on the web, and felt indicted by the thesis of the book, which, it
seemed to me, boiled down to the idea that the Web was making us stupid.
I had built a career around web technology and I wasn’t interested in
reading anything that questioned whether the web was a net positive.
Recently, in light of all that’s going on with AI at the moment, and
mycriticaltakes on it, I
thought perhaps I had dismissed Carr’s book too quickly. Just how long
has this project been going on? Did Carr see where things were headed? I
mentioned the idea, and a few other people agreed to do a
popup bookclub about it.
I’m glad I did get around to reading it finally. I got Carr wrong, he
was (is?) a fan of the web, just like I was at the time. But noticing a
decline in his ability to focus for long periods prompted him to
research and write The Shallows. He draws on the history of the book,
media studies and the history of technology more generally to illustrate
how technologies like clocks, maps, writing, and the book shaped how we
remember and thought itself. In the second half of the book he talks
about how the invention of the universal
machine (the computer) has effectively absorbed prior forms of media
into computers, as hypermedia. I don’t think Carr explicitly mentions
the concept of Remediation(Bolter & Grusin, 1996) here, but I
thought it was interesting to see how he connects media to the
computer’s ability to simulate other machines. He also brings in
neurology and psychology research literature to explain how different
phases of memory formation are disturbed by rapid attention shifts that
browsing the web affords:
The Web provides a convenient and compelling supplement to personal
memory, but when we start using the Web as a substitute for personal
memory, bypassing the inner processes of consolidation, we risk emptying
our minds of their riches. (Carr, 2011, p. 192)
I thought this line of critique was especially interesting in light of
the recent popularization of AI in the form of “chatting” with Large
Language Models (LLM) like ChatGPT. ChatGPT’s interface provides a
smooth surface where you conversationally interact with a computer to
obtain information. It doesn’t give you citations, or links to things on
the web to consult. Instead it gives you an answer, and you either
continue the clarify what you are looking for, move on to something else
or decide to stop. You don’t see a list of search results, which you
need to click on and move laterally into, to see if they contain the
answer to your question. These documents could have distracting design
components, ads or other boilerplate. You don’t need to read the linked
documents. ChatGPT seductively bypasses all that and you read The
Answer. Much to my dismay, it seemed like perhaps the affordances
of ChatGPT style interaction may not present the same problems as
classic web navigation, at least in terms of distractions that lead to
quick context shifts, and disturb our ability to form memories? I
imagine there are hordes of education and pyschology researchers looking
into this as a type, or they already have.
It was bit surreal reading the detailed descriptions in the final
chapters about how neurons store memories through repetitive training …
which echo the same language that is used to talk about deep learning
today. These are powerful metaphors that have been deployed. Almost
anticipating recent developments in AI, Carr ends the book talking about
the goals of classic AI, and specifically the warnings of Joseph
Weizenbaum in his book Computer
Power and Human Reason.
What Makes us most human, Weizenbaum had come to believe, is what is
least computable about us–the connections between our mind and our body,
the experiences that shape our memory and our thinking, our capacity for
emotion and empathy. The great danger we face as we become more
intimately involved with our computers–as we come to experience more of
our lives through the disembodied symbols flickering across our
screens–is that we’ll begin to lose our humanness, to sacrifice the very
qualities that separate us from machines. The only way to avoid that
fate, Weizenbaum wrote, is to have the self-awareness and the courage to
refuse to delegate to computers the most human of our mental activities
and intellectual pursuits, particularly “tasks that demand wisdom”.
(Carr, 2011, pp. 207–208).
Weizenbaum was the creator the original chatbot Eliza. I didn’t realize
that his experience of seeing how ELIZA was used prompted him to
critique the goals of Artificial Intelligence community. Maybe it’s not
surprising because according to Carr Weizenbaum’s book was trashed by
leaders in the computer science community at the time. Perhaps digging
up a copy of Weizenbaum’s book might be interesting reading in light of
AI’s resurgence now.
The Shallows had lots of citations to current states of affairs,
demographics and statistics that gave authority to Carr’s arguments. But
these got a little bit repetitive at times, but the drudgery drives the
points home I guess. It is striking reading it 13 years later how much
the web has changed.
In discussing the technologies of literacy and the book I felt a little
bit like Carr’s would have benefited at looking at the book and literacy
as instruments of power, that mobilized colonialism and capitalist
extraction. I found myself thinking a lot about Bernard Stiegler while
reading The Shallows, especially for the idea that writing and
computational devices are memory prostheses, and that they are a
pharmakon (contain both a remedy and a poison). A quick Kagi search and
I can see Stiegler had a sequence
of lectures about Carr. So I guess they knew of each other?
Overall I enjoyed The Shallows, even though I’m still working as a web
developer. Nowadays I’m explicitly interested in the web’s role in
memory practices, and what can be done from an architecture and design
perspective to work against the grain of the web’s most pernicious
features. There are some good threads to tug on in The Shallows.
References
Bolter, J. D., & Grusin, R. (1996). Remediation.
Configurations, 4(3), 311–358.
Carr, N. (2011). The shallows: what the Internet is doing to our
brains. New York: W.W. Norton.
If you work in the tech sector you’ve almost certainly already seen the
story about the planted security vulnerability discovered in xz.
Most of the discussion I’ve seen around this so far has been suggesting
that this is a problem that open source software presents, implying that
for profit, closed source software is different.
Of course this is yet another reminder of how creators and maintainers
of open source software tools are not being supported to continue their
work, especially by the companies that use their software. But there’s
another important dimension: we really only learned about this story
because xz is an open source software project.
Andres Freund is a software engineer who discovered this vulnerability
seemingly by chance. He is very humble about it, but his expertise as a
software developer primed him to notice the problem and to report it in
a responsible way. Are large corporations immune to bad actors planting
security vulnerabilities in closed source proprietary software? Nope. In
fact, these vulnerabilities are valuable.
The difference is when this happens in closed source software we hear
about it as a critical vulnerability after the fact. The exploit is
patched and life (hopefully) moves on. But we very rarely hear about how
the bug was created, or have any window in on how or why it happened.
The difference with open source software is, well, it’s open. Freund and
others like Evan
Boehs were able to examine the public Github repository, and try to
piece together what happened.
Sadly, Microsoft’s reaction to the news was to remove the GitHub
repository from the public web. This means that all this evidence is now
hidden from view.
Freund’s email to the oss-security discussion list contained links to
the GitHub repository:
Now these are now all broken. However it’s heartening to see that
someone had the foresight to archive these using the Internet Archive’s
Wayback Machine’s Save Page Now feature:
There is a surprising amount of respect for people who appear to know nothing about the industry. They’re known as the “left curves.”
The nickname comes from a popular meme in crypto that shows a bell curve with investors on the left who know nothing, or very little, and those in the fat middle of the curve who know something about crypto. On the right are investors who seemingly know everything.
Below the fold I look at the left side of the curve
Why does Shen think those who know nothing about cryptocurrencies are the big winners? Because they are jumping in to yet another cruptocurrency bubble:
For example, a crypto project with pseudonymous co-founders including “Smokey The Bera” and “Dev Bear” has become a unicorn after it raised millions of dollars from institutional investors such as Brevan Howard Digital. Another token with no real utility — only a cute picture of a dog wearing a hat — has increased by more than 1,400 times its value from three months ago. A developer of a sloth-themed memecoin called Slerf claimed they accidentally burned a large amount of the tokens after raising $10 million.
What a great time to be a left curve! In this bull market, forget about highbrow ideas like revamping Wall Street. Give up on dreams of replacing traditional artwork with nonfungible tokens. Instead, don’t overthink it. Just “choose rich.”
Well, yes, but the much-desired retail traders don't seem convinced. Even the mania around spot Bitcoin ETS has died down, as the chart shows. Shen writes:
How did this happen? How did crypto’s greatest comeback take place so fast, so hilariously and — at times — so stupidly? Why did crypto evangelists give up their dreams? At its core, it’s because the market is still living under the shadows of past catastrophes like FTX’s collapse and TerraUSD’s blowup.
In the past bull markets, when Bitcoin went up, everything else went up amid small-scale rotations between major and small-cap coins. But in this bull market, the rotation is more severe: As Solana went up in the past month, the price of Ether went down dramatically — a simple piece of evidence that shows there’s less money being thrown at the crypto market today than three years ago.
The "past catastrophes like FTX’s collapse and TerraUSD’s blowup" may be old news but to their victims they aren't even close to over. The best FTX's creditors can hope for is to get back what their HODL-ings were worth before Bitcoin took off moon-wards, and who knows when that might happen.
"I had no idea who Barry Silbert was or anything until after November 16, 2022," Eric Asquith told me. That date was when he was pretty sure he had lost his family’s savings of $1,052,000.
He didn’t buy bitcoin or other meme tokens. Instead, earlier that year, he moved over cash from his business — just a little at first, then more — and converted it into digital currencies he thought were as good as cash. The digital coins were called GUSD, and each was worth exactly $1 because the company that minted them — Tyler and Cameron Winklevoss’s crypto exchange, Gemini — backed each one with real money and assets.
But Asquith's GUSD were deposited into Gemini's Earn program to get its 5.5% interest, far more than banks were paying. But Asquith and the other Earn depositors were far enough left on the curve that they didn't know Earn wasn't like a bank savings account:
What Asquith did not fully understand was that his money was no longer with Gemini. In one sense, Genesis, a crypto company owned by Barry Silbert had it, but even that wasn’t quite true. Soon-to-collapse hedge funds with names like Three Arrows Capital and Alameda Research — Sam Bankman-Fried’s personal fund — were quietly borrowing from Silbert’s shop. Asquith’s money, and that of tens of thousands of others, was being used by SBF and others to make giant bets on some of the highest-flying, most volatile digital tokens.
Then Terra/Luna collapsed and things started to fall apart. Amy Castor and David Gerard reported:
One of Genesis’s biggest customers was Three Arrows Capital (3AC), who they’d lent $2.4 billion. After 3AC blew up in May, DCG assumed $1.2 billion of the liabilities to keep the hit off Genesis’ books. Genesis had been the single largest creditor of 3AC.
Genesis also had money on FTX. As FTX was falling apart, Genesis tweeted on November 8 that they had no exposure, and it was fine. Two days later, Genesis admitted they had “~$175M in locked funds in our FTX trading account,” and they were not fine.
Genesis scrambled to find more capital. Genesis and DCG needed $1 billion in emergency credit by 10 a.m. EST on November 14, but didn’t get it. Even Binance turned them down.
So two days later, Genesis suspended withdrawals,
...
One of Genesis’s biggest customers is Gemini Trust, run by the Winklevoss twins, that operated its own “yield” program, Gemini Earn, for retail investors.
Gemini was supposed to be the safe exchange — but it was exposed to risks via Genesis. There’s now $700 million that Gemini Earn customers can’t withdraw — because it’s stuck on Genesis.
On January 8, Gemini terminated the Master Loan Agreement with Genesis and emailed customers accordingly. This “requires Genesis to return all outstanding assets in the program.” Genesis did not return the funds by the end of January 10 — so they were officially in default on the loan. At this point, Genesis can pull the pin and try to put Gemini into involuntary bankruptcy.
They did, and there followed a year of legal wrangling between Gemini, Genesis and Barry Silbert's Digital Currency Group, which owns Genesis. The SEC sued both Gemini and Genesis, and so did the New York Attorney General.
While the wrangling continued, another of the semi-regular cryptocurrency bull markets took off until in February 2024:
the victims, Silbert’s now-bankrupt crypto-lending operation, the Winklevoss twins, and regulators hammered out a deal to pay everybody back in full. The crypto bull market of 2024 made it possible to pay back Earn customers not some fraction of what they invested but the generally much higher sum of what their holdings would now be worth.
Except there was Silbert. Earn victims who had been unfamiliar with him would soon learn that he had made his first fortune by studying the ins and outs of the bankruptcy system and using it to his financial advantage. Since February, the billionaire investor has been relying on a controversial interpretation of bankruptcy law to stop Asquith and all the other victims from getting the bigger payout, the one based on current prices. Instead, to simplify a bit, he would prefer to keep that money himself. “DCG cannot support a plan that not only deprives DCG of its corporate governance rights but also violates United States bankruptcy code,” a spokeswoman for the company said.
The victims have taken to calling it “the Barry Trade”: If Silbert is successful, he would be able to pocket as much as $1 billion in funds that would otherwise be returned to them. At the very least, Silbert may substantially delay the money being returned to Earn customers.
...
Silbert’s legal logic is that the bankruptcy code sets a date to value victims’ claims in U.S. dollars, and in Genesis’ case, it just happened to be around the market’s lows.
Former Gemini employees told The Beast that Gemini Earn’s terms and conditions were highly dubious from the outset. One staffer recalled reading the fine print for the first time, saying, “[We] were like, ‘Holy shit, are you fucking kidding me?’”
Among those terms: Customer assets were loaned out on “an unsecured basis,” which meant that their money would not be safe in the event of a market collapse. The deposits were also not insured, nor were they guaranteed against errors or fraudulent activity.
“Whatever Gemini may or may not have done pales in comparison to what you see at Genesis, which was more than negligent when it came to protecting customer assets and complying with general best practices,” one former employee said. Among those problems, the person said, was not screening clients who were on, say, the Treasury’s blacklists — an allegation that was supported by a separate January suit filed by New York Department of Financial Services.
A ruling isn’t expected until April. Since the settlement announcement, the victims have resigned themselves to an even longer wait as Silbert continues to fight. “A year ago, there was a deal that was proposed. Everyone was celebrating in a very similar way,” Asquith said. “Now, I’ll believe it when it’s in my account.”
A project describing itself as "The world's first memecoin pre-announced as a rugpull" was explicit in its marketing: "do not buy this coin, as it will go to zero."
Despite that, people sent the creator over 8.8 ETH (almost $29,000) for the project's "pre-sale", even as they repeated on Twitter that the project was a scam and that no one should buy it.
Between March 5 and 6, 2024, Caracas, capital of the Bolivarian Republic of Venezuela, could not be left behind in the celebration of Open Data Day 2024; and the UTOPIX Femicide Monitor was in charge of it. During these two days a workshop was held: “Bootcamp INFOTOPIA version 2.0: Learning to monitor and infographics gender violence in the Capital District”.
This event was attended by 20 representatives of various feminist and women’s organizations from the states of Distrito Capital, La Guaira, Aragua and Miranda. On the first day, they received an introduction to monitoring data on various types of gender violence through the open source method; and on the second day, they received training on a visual tool for mass dissemination as important as infographics.
The facilitator was myself, Aimee Zambrano, on the first day and on the second day I was accompanied by Kael Abello, both founding members of the UTOPIX community and communication platform.
The main topics addressed during the Bootcamp were:
Media monitoring and data collection.
Concepts: the difference between communication and information; information systems;
Monitoring and follow-up of information;
Systematization of information;
Open data analysis: open data and web scrapping;
Data Monitoring Strategies;
Some simple tools for data monitoring.
INFOTOPIA method: it is a collaborative dynamic for the visual processing of information and collective generation of infographic materials.
Thinking data: a brief review of the fundamental elements of the infographic conception to delimit the criteria, categories and hierarchies of the data.
From writing to image: A tour of tools that make it possible to infographically display information in a simple way.
Among the main topics addressed by the various organizations as possible projects to be accompanied by the UTOPIX Monitor for their subsequent development into infographics and publication in social networks, the following stand out:
Women’s autonomy, advances in sexual and reproductive rights.
Discrimination against Sapphic women in Venezuela during 2023.
Implicit violence in the experiences of Yukpa indigenous craftswomen and craftsmen.
Psychological violence in the Altagracia parish: July-December 2023.
Indigenous women’s leadership in Venezuela, remains and risks.
Exploitation and sexual abuse of Venezuelan migrant women in Latin America.
The idea is that this Bootcamp is the first of many workshops that we want to dictate in several states of the country, to train various feminist and women’s organizations to start a monitoring network of gender violence in Venezuela.
About Open Data Day
Open Data Day (ODD) is an annual celebration of open data all over the world. Groups from many countries create local events on the day where they will use open data in their communities.
As a way to increase the representation of different cultures, since 2023 we offer the opportunity for organisations to host an Open Data Day event on the best date within a one-week period. In 2024, a total of 287 events happened all over the world between March 2nd-8th, in 60+ countries using 15 different languages.
All outputs are open for everyone to use and re-use.
In 2024, Open Data Day was also a part of the HOT OpenSummit ’23-24 initiative, a creative programme of global event collaborations that leverages experience, passion and connection to drive strong networks and collective action across the humanitarian open mapping movement
For more information, you can reach out to the Open Knowledge Foundation team by emailing opendataday@okfn.org. You can also join the Open Data Day Google Group to ask for advice or share tips and get connected with others.
The basic idea is that we want to combine web archives with an
existing large language model, so that the model will answer questions
using the contents of the web archive as well as its inherent
knowledge. I have for many years run a wiki for myself and a few
friends, which has served variously as social venue, surrogate memory,
place to pile up links, storehouse of enthusiasms. When Matteo first
announced WARC-GPT, it struck me that the wiki would be a good test;
would the tool accurately reflect the content, which I know well?
Would it be able to tell me anything surprising? And more prosaically,
could I run it on my laptop? Even though the wiki is exposed to the
world, and I assume has been crawled by AI companies for inclusion
into their models (despite the presence of a restrictive robots.txt),
I don’t want to send those companies either the raw material or my
queries.
What is a web archive
Briefly, a web archive is a record of all the traffic between a web
browser and a web server, for one or more pages—from which you can
recreate the playback of those pages. My first task was to generate a
list of the 1,116 pages in the wiki, then create an archive using
browsertrix-crawler,
with this
command,
which produced the 40-megabyte file
crawls/collections/wiki/wiki_0.warc.gz. This is a WARC file, a
standard form of web archive.
Ingest the web archive
We now turn to WARC-GPT; the next step is to ingest the web archive,
an optional step is to visualize the resulting data, and the last step
is to run the application with which we can ask a question and get an
answer.
I installed WARC-GPT by running
git clone https://github.com/harvard-lil/warc-gpt.git
cd warc-gpt
poetry env use 3.11
poetry install
I copied
.env.example
to .env and made a couple of changes recommended by Matteo (of which
more later), then copied wiki_0.warc.gz into the warc/
subdirectory of the repo. The command to process the archive is
poetry run flask ingest
which… took a long time. This is when I started looking at and
trying to understand the code, specifically in
commands/ingest.py.
What is actually going on here
In the ingest step, WARC-GPT takes the text content of each captured
page, splits it into chunks, then uses a sentence
transformer to turn the text into
embeddings, which are vectors of numbers. It later uses those
vectors to pick source material that matches the question, and again
later in producing the answer to the question.
This is perhaps the moment to point out that AI terminology can be
confusing. As I’ve been discussing all this with Matteo, we
continually return to the ideas that the material is opaque, the
number of knobs to turn is very large, and the documentation tends to
assume a lot of knowledge on the part of the reader.
The first setting Matteo had me change in the .env file was
VECTOR_SEARCH_SENTENCE_TRANSFORMER_MODEL, which I changed from
"intfloat/e5-large-v2" to "BAAI/bge-m3". This is one of the knobs
to turn; it’s the model used to create the embeddings. Matteo said, “I
think this new embedding model might be better suited for your
collection…. Main advantage: embeddings encapsulate text chunks up
to 8K tokens.” That is, the vectors can represent longer stretches of
text. (A token is a word or a part of a word, roughly.)
One of the other knobs to turn, of course, is where you run the
ingest process. Matteo has been doing most of his work on lil-vector,
our experimental AI machine, which is made for this kind of work and
is much more performant than a Mac laptop. When I ran an ingest with
BAAI/bge-m3, the encoding of multi-chunk pages was very slow, and
Matteo pointed out that the parallelization built into the encoding
function must be running up against the limits of my computer. I
turned an additional knob, changing
VECTOR_SEARCH_SENTENCE_TRANSFORMER_DEVICE from "cpu" to
"mps"—this setting is, roughly, what hardware abstraction to use in
the absence of a real GPU, or graphics processing unit, which is where
the work is done on machines like lil-vector—but I didn’t see a big
improvement, so I set out to make the change I
mentioned at the
beginning of this post. The idea is to keep track of encoding times
for one-chunk pages, and if encoding a multi-chunk page takes a
disproportionately long time, stop attempting to encode multiple
chunks in parallel.
This worked; ingest times (on my laptop, for my 1,116-page web
archive) went from over an hour to about 38 minutes. Success! But note
that I still don’t have a clear picture of how ingest time is really
related to all the variables of hardware, settings, and for that
matter, what else is happening on the machine. Further improvements
might well be possible.
Also note that the pull
request contains
changes other than those described here: I moved this part of the code
into a function, mainly for legibility, and changed some for-loops to
list
comprehensions,
mainly for elegance. I experimented with a few different arrangements,
and settled on this one as fastest and clearest, but I have not done a
systematic experiment in optimization. I’m currently working on adding
a test suite to this codebase, and plan to include in it a way to
assess different approaches to encoding.
Coda
You will notice that we have not actually run the web application, nor
asked a question of the model.
When Matteo suggested the change to the sentence transformer model, he
added, “But you’ll also want to use a text generation model with a
longer context window, such as:
yarn-mistral“—the point
Matteo is making here that when the sentence transformer encodes the
input in larger pieces, the text generation model should be able to
handle larger pieces of text. The implicit point is that the text
generation model is external to WARC-GPT; the application has to call
out to another service. In this case, where I wanted to keep
everything on my computer, I am running Ollama,
an open-source tool for running large language models, and set
OLLAMA_API_URL to "http://localhost:11434", thereby pointing at my
local instance. (I could also have pointed to an instance of Ollama
running elsewhere, say on lil-vector, or pointed the system with a
different variable to OpenAI or an OpenAI-compatible provider of
models.)
Once Ollama was running, and I’d run the ingest step, I could run
poetry run flask run
and visit the application at http://localhost:5000/. I can pick any of
the models I’ve pulled with Ollama; these vary pretty dramatically in
speed and in quality of response. This is, obviously, another of the
knobs to turn, along with several other settings in the interface. So
far, I’ve had the best luck with mistral:7b-instruct-v0.2-fp16, a
version of the Mistral model that is optimized for chat
interfaces. (Keep an eye out for models that have been quantized:
model parameters have been changed from floating-point numbers to
integers in order to save space, time, and energy, at some cost in
accuracy. They often have names including q2, q3, q4, etc.) The
question you ask in the interface is yet another knob to turn, as is
the system
prompt
specified in .env.
I haven’t learned anything earth-shattering from WARC-GPT yet. I was
going to leave you with some light-hearted output from the system,
maybe a proposal for new wiki page titles that could be used as an
outro for a blog post on querying web archives with AI, or a short,
amusing paragraph on prompt engineering and the turning of many knobs,
but I haven’t come up with a combination of model and prompt that
delivers anything fun enough. Stay tuned.
An 8 April webinar from the Balboa Park Online Collaborative features Dr. Piper Hutson discussing inclusive design, with a focus on sensory processing and neurodiversity. The session’s goal is to empower organizations with the understanding and resources needed to rethink their environments, displays, and activities with inclusivity in mind. Attendees will be introduced to tactics and methods to incorporate neurodiversity-friendly approaches at their institutions, including: understanding the diverse ways people interact with cultural settings; utilizing technology to bolster accessibility; and cultivating an environment of organizational empathy and comprehension.
Museums have been working towards creating spaces and experiences that are more friendly to neurodiverse people. These efforts can offer many lessons to libraries and archives that are pursuing similar goals. Plus, this is a teaser for ALA 2024, when we can meet in person to take in all Balboa Park has to offer! Contributed by Richard J. Urban.
Metadata training materials for DEIA
Like many organizations concerned with issues of Diversity, Equity, Inclusion, and Accessibility, the Music Library Association (MLA) has required members who participate in any part of its administrative structure to keep current with training on implicit bias, anti-racism, and other aspects of cultural competency. MLA’s Cataloging and Metadata Committee (CMC) has compiled a list of recent presentations, webinars, best practices, and other publications that both fulfill MLA’s directive and are of more general interest. “Metadata-Focused DEIA Training” includes links to programming presented at past MLA and other professional conferences and OCLC Cataloging Community Meetings. Several of the recordings also include lists and links to additional related material.
Although the focus of this list is, naturally, on metadata, these freely-available online resources range far beyond cataloging, let alone just music cataloging. Ethical and inclusive description of library materials stands at the center of so much of what libraries do. There is so much work that needs to be done to repair outdated terminology and practices, that an awareness by everyone in the library ecosystem strengthens the institution at large. Contributed by Jay Weitz.
In Brief: Despite a growing pool of research in library and information science (LIS) authored by autistic librarians (see Lawrence, 2013; Tumlin, 2019), the vast majority of LIS research about autistic students in academic libraries continues to portray autism as a tragedy that students must overcome, a common trope that the autistic community has long rallied against (Sinclair, 1993). In this article, I recommend that those writing about autistic students and academic libraries do so through a neurodiversity lens; those who ascribe to the neurodiversity paradigm generally conceive of variation in neurocognitive functioning as a valuable and natural aspect of human diversity (Walker, 2021). Making this paradigm shift in name alone, however, will not be enough. Effecting true change in LIS research will involve deep reflection on the values and norms of academia as well as those of librarianship. As a profession concerned chiefly with information, and as academic librarians tasked with supporting college students of all neurotypes during their formative years, we must begin to interrogate the ways in which our research and professional practices may themselves create barriers to the inclusion and full participation of autistic students in our libraries.
Due to increased transition supports, greater access to diagnostic services, and increased knowledge about how autism presents in women, people of color, and other marginalized groups, a greater number of autistic students are attending higher education institutions (Bakker et al., 2019). Though autism was once inaccurately conceived of as a childhood phenomenon that a person could outgrow, it is now more accurately understood as a distinct neurotype associated with a diverse range of support needs and strengths that may vary for individuals across contexts and time. Autism-focused research in library and information science (LIS) has become increasingly common in recent years, and academic librarians have begun to address the needs of this growing population of autistic students in higher education through both research and practice (Anderson, 2018; Anderson, 2021; Robinson & Anderson, 2020; Pionke et al., 2019; Remy et al., 2014).
Yet despite increased postsecondary enrollment, autistic students still experience myriad barriers to academic success and graduation, many of which stem from systemic ableism within higher education and society more broadly. Academic libraries have long been recognized as a key resource for college student success, and autistic students in particular may value the library as a place of escape and refuge within the unstructured and overstimulating college environment (Anderson, 2018). With the understanding that academic libraries may be of particular help in supporting autistic students’ success, an increasing number of autism-focused articles have appeared in LIS journals within recent years. Despite the good intentions undoubtedly underlying this line of research, much of what has been written about autistic students in academic libraries serves to perpetuate the same inaccurate and harmful stereotypes that appear in autism research across other disciplines (Botha & Cage, 2022). One potential solution to this ongoing problem is the adoption of the neurodiversity paradigm within library and information science research.
What is the Neurodiversity Paradigm?
Autistic scholar Nick Walker defines the neurodiversity paradigm as a perspective that appreciates neurodiversity as a “natural and valuable form of human diversity,” rejects the socially constructed notion that there is a “normal” and correct kind of “neurocognitive functioning,” and recognizes that “social dynamics” and structural inequities related to neurodiversity are similar to those experienced by other marginalized groups (2021, p. 36). E.E. Lawrence, an autistic LIS scholar, called for the adoption of the neurodiversity paradigm in LIS research and practice in his 2013 essay “Loud Hands in the Library: Neurodiversity in LIS Theory & Practice.” To my knowledge, Lawrence is the first LIS scholar to problematize the way in which research by and for library professionals has failed to adopt the neurodiversity paradigm, resulting in LIS research that dehumanizes and pathologizes autistic people. In his essay, Lawrence argues that librarians have “a special obligation to generate theory, policy, and practice that is consistent with neurodiversity” (2013, p. 99). While Lawrence notes that library professionals may view this call for adopting the neurodiversity paradigm as a violation of librarians’ supposed professional neutrality, he adamantly disagrees, arguing that embracing and affirming neurodiversity is essential to our ability to provide equitable and effective library services to all patrons.
In what follows, I argue that despite multiple calls from autistic LIS professionals like Lawrence (2013), the vast majority of researchers in the field have failed to truly adopt the neurodiversity paradigm. With a focus on literature published since 2013, I explore the ways in which academic librarians have written about autistic people, highlighting examples that are in tension with the neurodiversity paradigm and those that suggest progress toward affirming neurodiversity in our research and practice. In particular, I problematize the paradoxical nature of research that purports to better support a patron population while simultaneously dehumanizing those same people. Finally, I contend that this paradigm shift within our profession would necessitate a reckoning with our espoused values and our behavior as researchers and practitioners, especially in relation to evidence, authority, and credibility.
Reviewing the Literature
The majority of publications regarding autistic students in academic libraries within the last ten years have addressed the need for increased staff training, the adoption of universal design, and the creation of specific programs to support autistic students (Anderson, 2018; Anderson, 2021; Boyer & El Chidiac, 2023; Layden et al., 2021; Pionke et al., 2019; Remy et al., 2014; Robinson & Anderson, 2022; Walton & McMullin, 2021). Many conceptual pieces describe the support needs of autistic students, typically drawing upon autism research from medicine, psychology, and education, and applying findings from this body of research to recommend approaches to academic library services (Carey, 2020; Cho, 2018; Everhart & Anderson, 2020; Shea & Derry, 2019). Despite the fact that this research is undoubtedly rooted in the goal of helping library staff to better support autistic students, much of the recent LIS scholarship about autistic college students continues to reinforce deficit-based views about autism, in part due to the (sometimes unacknowledged) use of the medical model of disability as a lens.
Models of Disability
At present, there is no clear consensus within the neurodiversity community, or the disability community at large, regarding a universally preferred model of disability. The various models of disability each conceptualize disability and its origins differently, with the medical and social models often conceived of as being particularly at odds. While the medical model defines disability as an individual phenomenon, where disabled people are inherently abnormal, deficient, and in need of remediation (Botha & Cage, 2022), the social model identifies societal barriers and a lack of accommodations as the factors that render people disabled (Shakespeare, 2013). Critics of the medical model cite its focus on fixing the individual as problematic, while critics of the social model argue that a primary focus on societal barriers overshadows the reality of impairments and the challenges that may arise from them. When it comes to embracing the neurodiversity paradigm, however, Walker (2021) claims that the medical model of disability is incompatible, and she argues for the use of the social model by those who adopt a neurodiversity lens for their research and practice. Though I recognize the potential shortcomings of the social model for some disability experiences, I find Walker’s argument convincing in the context of neurodiversity and autism, which I believe to be natural and neutral examples of human diversity.
The description of autistic college students through a medical model lens in LIS research is a common and problematic practice, but what is especially troubling about this practice is that many authors whose work aligns with the medical model claim to be proponents of the social model. Several authors of recent LIS publications about autistic college students describe different models of disability (Remy et al., 2014; Robinson & Anderson, 2022), or even recommend the adoption of the social model in future studies (Shea & Derry, 2019). Still, the majority of researchers continue to describe the challenge autistic students face as arising from their autistic traits, rather than from the ways in which institutions of higher education are designed for neurotypical students, who are also frequently inadequately supported by our systems.
One of the often-cited barriers to academic success for autistic students is the fact that many disabled students, including autistic students, choose not to disclose their disability to their college or university (Cho, 2018; Everhart & Escobar, 2018; Remy et al., 2014). While lack of disclosure and a corresponding lack of support services are noted in these works, few, if any, acknowledge the systemic issues that would lead a disabled person to avoid disclosing their diagnoses and support needs. There is a wealth of research regarding the discrimination disabled students face when attempting to navigate the academic accommodations process, including social stigma, disbelieving faculty, and stringent documentation requirements (Lindsay et al., 2018) that these LIS publications do not acknowledge. Instead, some researchers have attributed an avoidance of disclosure as a hesitance to be “classified by their disability and labeled ‘disabled’” (Everhart & Escobar, 2018, p. 270) or “receive undue attention” (Remy et al., 2014) without any discussion of the social contexts, systems, and individual behaviors that create an environment in which the disability label becomes problematic.
This same framing is often used to describe the higher rates of attrition among autistic students in higher education as compared to neurotypical peers. For example, Robinson and Anderson (2022) cite a “number of factors that contribute to this attrition, including difficulty transitioning to higher education, mental health difficulties, and low socioeconomic status” (p. 164). The authors go on to discuss common challenges autistic students face, including struggles with time management and self-advocacy, noting that these students “consequently…have a graduation rate that is significantly lower than neurotypical students” (Robinson & Anderson, 2022, p. 161). While these statements are not objectively false, and autistic students do often struggle with executive functioning, self-advocacy, and mental health, the manner in which these challenges are framed does not contextualize autistic students’ struggles as occurring within a larger social and academic context that is designed with nondisabled students in mind.
These rhetorical choices exist in direct tension with the authors’ description of the social and medical models of disability, as well as their recommendation that the neurodiversity framework could be useful in explaining challenges neurodivergent students face in higher education. This tension is present in a number of publications, many of which advocate for greater staff training about the needs of disabled patrons (Anderson, 2018; Remy et al., 2014) while still framing the challenges autistic students face as existing primarily due to their autism, rather than arising from a mismatch between expectations and supports, or an interaction between impairment and context.
In adopting a neurodiversity lens, I recommend that LIS scholars thoughtfully examine the theoretical underpinnings of the ways in which they explain the challenges autistic students face in higher education. While the social model may not be appropriate framing for the experiences of every disabled person, I agree with Walker (2021) that the social model is the most appropriate option for neurodiversity-informed research. The social model does not deny the existence of impairment or the need for supports, as some critics suggest, but it does distinguish between an impairment, such as low vision, and the disablement that comes from not being able to participate fully in society due to systemic barriers (Shakespeare, 2013). Adopting the neurodiversity paradigm, which engages with the constructed nature of disability alongside the reality of individual impairment, will mean finding ways to describe needed supports without dehumanizing those who would benefit from them. This shift will require making less harmful and more accurate choices regarding the language used to describe autistic people in LIS research.
The Impact of Language
An unfortunate consequence of the medical model lens used in much of autism research in LIS is that much of the language used to describe autistic people and their traits is dehumanizing and pathologizing in nature. Among the most jarring inconsistencies is the use of the term “deficit” in articles that claim to be aligned with the social model of disability, which primarily understands disability is a socially constructed phenomenon arising from barriers to full participation by disabled people (Lawrence, 2013). By claiming that autistic people are deficient in certain skills or traits, a comparison is made to an unspoken, undefined norm, casting autistic people as inherently inferior and abnormal. Some authors even go so far as to claim that autistic students face challenges in higher education and academic libraries “because of these deficits” (Shea & Derry, 2019, p. 326, emphasis added), which is in alignment with a medical model understanding of autistic students’ experiences.
The choice to use such pathologizing language is often defended as the expectation for scientific research. Cho (2018), for example, notes that their work is grounded in “the scientific understanding of ASD as a disorder” (p. 329). In their recommendations for avoiding ableist language in autism research, Bottema-Beutel and colleagues (2021; 2023) note that researchers often justify deficit-based language choices as scientific, citing concerns that less ableist terminology could be construed as inaccurate and unscientific. Despite this reasoning, many authors utilize deficit-based phrasing that in itself is vague and often inaccurate, including functioning labels. Functioning labels are a hotly debated issue in autism research, though “few autistic adults, family members/friends, or health care professionals endorse the use of functioning-level descriptors” (Bottema-Beutel et al., 2021, p. 23). While many of the articles cited here use the term “high-functioning” to describe autistic college students (Anderson, 2018; Cho, 2018; Everhart & Anderson, 2022; Everhart & Escobar, 2018; Remy et al., 2014), few actually articulate what this means within the context of their research or for the autistic students their readers will support in their own libraries. This is not a LIS research-specific phenomenon; functioning labels tend to be extremely vague across autism research in a variety of disciplines, and often serve only to “assign expectations,” reducing autistic “people to ‘human doings’ instead of human beings” (Tumlin, 2019, p. 13). Despite the dehumanizing nature of these language choices, authors of these same publications often insist on using person-first language to describe autistic people.
Though person-first language (i.e. person with autism) was once touted as the gold standard in special education, it has now come to be understood as less universally preferred among the highly heterogeneous disability community (Bottema-Beutel et al., 2021). Many autistic people, in particular, have come to prefer identity-first language (i.e. autistic person), recognizing autism as a key part of their identity, inseparable from their selfhood (Sinclair, 2013). Proponents of person-first language insist that acknowledging autistic people’s personhood is paramount, but autistic scholars have noted that the need to be reminded that autistic people are human beings, as if it is not automatically apparent, is dehumanizing in itself (Sinclair, 2013). Despite a critical mass of the autistic community advocating for a shift in language to affirm and validate autistic identities, research has lagged behind, overwhelmingly tending to favor person-first language, often in combination with the word “disorder” (Bottema-Beutel et al., 2021; Lawrence, 2013; Sinclair, 2013).
Interestingly, multiple LIS scholars have acknowledged a preference in the autistic community for identity-first language, but explicitly choose to align their own language use with mainstream autism research (e.g. Anderson, 2018; Shea & Derry, 2019). Even more troubling, some authors who use person-first language throughout their text also refer to autistic people as “ASDs,” an odd term based on the initialism for Autism Spectrum Disorder that feels uniquely dehumanizing among the many possible language choices at hand (e.g. Braumberger, 2021; Remy et al., 2014; Robinson & Anderson, 2022).
The language used in these publications reflect the ongoing lack of engagement with the neurodiversity paradigm in our field, despite the occasional references to neurodiversity-inspired terminology in this same research. Terms developed by neurodiversity scholars appear occasionally in LIS research focused on autistic students in academic libraries, but few of these publications use the language consistently, accurately, and in a way that reflects the values of neurodiversity advocates. Autistic scholar Nick Walker (2021) describes a common pitfall regarding neurodiversity and language: using “neurodiverse” and “neurodivergent” interchangeably. While neurodiversity refers to the diversity of human minds and cognition, neurodivergence refers to those who diverge from the socially constructed neurotypical norm, including autistic people and those with ADHD, dyslexia, etc. (Walker, 2021). Others misuse the term neurotypical, generally understood to be those who are able to align with the socially constructed cognitive norm (Walker, 2021), claiming it to refer to allistic, or non-autistic, people (Everhart & Escobar, 2018) or failing to describe the ways in which ‘typical’ is a non-objective social construct (Walton & McMullin, 2021).
These misrepresentations, whether intentional or not, suggest that many LIS scholars have not engaged thoughtfully with the work of neurodiversity scholars. This is especially troubling when library researchers cite the work of the few known autistic LIS scholars, whose work calling for neurodiversity-informed LIS research is quite clear in its language and recommendations (Lawrence, 2013; Tumlin, 2019). Though some LIS scholars have indicated that they are aligning their language with professional and scientific standards, the language these authors often use is often vague and inaccurate (Bottema-Beutel et al., 2021) and “good science does not require derogatory language or dehumanization of autistic people” (Bernard et al., 2023, p. 683).
The neurodiversity framework conceives of the diversity of human cognition as natural, and even valuable, rather than as a deviation from a more desirable, “normal” brain. The adoption of such a mindset would require more precise language choices, particularly when the terminology we employ is linked to issues of power and positioning. For example, LIS researchers must acknowledge that “neurodiverse” is not a euphemism for “neurodivergent,” a term that does not mean abnormal, but a deviation from the socially constructed norm for human cognition (Walker, 2021). Explicit recognition of the ways in which unspoken, undefined (and often undefinable) norms are used to Other marginalized groups, including neurodivergent people, is a key feature of neurodiversity-informed research. Language choices that pathologize certain ways of perceiving, thinking, and being in the world are incompatible with this framework.
It is imperative that the LIS field recognize the powerful nature of the language choices we make, both for the understanding of colleagues we hope to share our research with, and for the well-being autistic people (both patrons and colleagues) who come into contact with our work. Deficit framings of autistic people contribute to the ongoing marginalization of a group whose voices are already woefully underrepresented in research, and contribute to power dynamics in the field that prevent meaningful engagement with autistic collaborators and participants (Bernard et al., 2023), an essential feature of neurodiversity-informed LIS research.
Representation of Autistic Voices
Though some authors have cited the work of autistic LIS scholars Lawrence (2013) and Tumlin (2019) in their own work pertaining to autistic patrons in libraries, few have adopted the neurodiversity framework that both authors call for, and even fewer engage with autistic participants as part of their research. In one of the few LIS publications to report on findings from autistic participants, Pionke and colleagues (2019) note that much of the library literature published about autism does not actually draw upon the autistic experience. Other authors note that if the neurodiversity movement is to make headway in the field of library and information science, LIS scholars will need to interact with neurodivergent patrons to conduct their research, “as it is important not to speak for a population without gathering their input” (Everhart & Anderson, 2020, p. 4).
Several LIS studies within the past ten years, including the work of Pionke and colleagues (2019), have drawn upon autistic participants’ perspectives and offer examples of how neurodiversity-informed research might amplify autistic voices. In their 2019 study, Pionke and colleagues engaged directly with autistic students in their analysis of library support for Project STEP, a program for autistic college students. Anderson’s (2018) study of online communication among autistic students regarding their use of academic libraries, a publication from her dissertation data, is one of the first to acknowledge the importance of autistic people’s lived experiences and articulated preferences regarding library resources, spaces, and services. Were more LIS researchers to engage with the autistic students on their own campuses, there would likely be a greater number of studies that challenge outdated and harmful assumptions about autistic people, leading to more relevant and useful findings that will allow us to better serve our patrons.
A 2020 study of disabled students’ perceptions of academic library accessibility webpages (Brunskill, 2020), though not focused solely on autistic participants, is a prime example of the ways in which a researcher might not only engage with disabled participants, but also intentionally design a neurodiversity-informed study. Brunskill collaborated with disability studies faculty, including disabled faculty members, to design their interview protocol in a way that would avoid causing harm to their participants. Following a pilot of the interview protocol, Brunskill offered students control over the interview modality, a choice that not only aids in transferring some power to participants, but also reflects a neurodiversity- and disability-affirming approach, as different modalities may meet different participants’ needs and preferences.
Epistemic Injustice
While the issue of little engagement with autistic participants and colleagues in scholarship is not unique to our field, it is still troubling, and reflects a larger trend of failing to prioritize the voices of the marginalized groups we aim to support. Autistic scholar Remy Yergeau (2018) describes the way in which the narrative about autism and autistic people is one of non-agency and non-rhetoricity; autistic people are constructed as non-actors in their own lives, and non-speakers about their own experiences. Those who attempt to speak about the expertise derived from their lived experience are silenced on the basis of being either too autistic or not autistic enough to speak for the autistic community (Botha, 2021), a strategic and effective dismissal experienced by members of many marginalized groups. By prioritizing the preferences and voices of so-called autism ‘experts’ in LIS scholarship, we not only perpetuate harmful stereotypes about the people we seek to serve, but also discount the experts who could make our research and practice significantly more effective.
Autistic scholar Monique Botha (2021) describes the ways in which autism research routinely causes harm through such characterizations, which reinforce the dehumanizing portrayals of autistic people while ignoring very real evidence from autistic participants and scholars. Botha calls this “epistemic injustice,” a phenomenon in which autistic voices are continuously silenced and marginalized in favor of supposedly neutral and scientific research (p. 6). In short, “we do not trust, nor want autistic people to talk about autism” (Botha, 2021, p. 6). Until we, as a profession, begin to meaningfully collaborate with autistic students in our research, we will continue to perpetuate and affirm this harmful message.
This epistemic injustice also helps to explain why LIS scholars are not engaging with the work of autistic scholars to the degree that they engage with mainstream autism research. Several LIS studies mention, for example, that autistic students may struggle in social situations due to deficits in social communication skills (Anderson, 2018; Everhart & Escobar, 2018; Shea & Derry, 2019). These characterizations of communication challenges arising from autism alone disregard the well-known work of autistic scholar Damian Milton (2012), who coined the term the “double empathy problem” to describe the interactional communication challenges between autistic and non-autistic interlocutors, arising from a communication mismatch rather than from autistic deficits. Crompton and colleagues (2020) confirmed through experimental research that autistic individuals communicate effectively with one another, lending further credence to Milton’s theory of the double empathy problem.
Milton’s work, alongside the work of other autistic autism researchers, is often uncited in LIS publications, which tend to favor more traditional and conservative notions of expertise and authority. While these choices may seem neutral and aligned with science, as many claim them to be, I argue that no choice is apolitical, especially when scholars hold the power to contribute to the problematic positioning of a marginalized group they believe their research supports. To begin the journey toward adopting a more humanizing, neurodiversity-informed approach to LIS research, we must first ask ourselves why this change has not already been made.
A Professional Reckoning
Ten years after Lawrence’s (2013) “Loud Hands,” a key question remains: why have academic librarians failed to heed our colleagues’ calls to adopt the neurodiversity paradigm as a framework for our research about autistic students? I contend that this ignorance, and in some cases, outright refusal, to engage with neurodiversity is in direct tension with our espoused professional values and the information literacy dispositions we aim to cultivate in our students. This issue also reflects a larger tension within our profession regarding who we deem to be an authority, and whether we are willing to critically engage with the ways in which power and systemic oppression impact who is perceived as authoritative.
As academic librarians, we regularly teach students that “authority is constructed and contextual” (Association of College and Research Libraries (ACRL), 2015), and that credibility, evidence, and authorship are not always to be taken at face value. Though we employ the ACRL Framework (2015) to foster a critical stance toward authority in our students, thus far, our field has failed to take this same stance in our own research about autistic students in academic libraries. Instead, the majority of this research perpetuates the notion that autistic people are, at best, abnormal and in need of remediation, and at worst, inhuman and non-rhetorical (Yergeau, 2018), unable to serve as experts on our own experience.
Andrea Baer (2023) recently problematized the ways in which the LIS field has uncritically accepted the “dominant narrative” of a post-COVID world, a narrative that is contradicted by reputable data about disease transmission. She notes how the rhetoric surrounding the ongoing death toll of COVID has been described as occurring predominantly in the elderly and people with pre-existing conditions, and those who continue to take precautions to protect themselves and others are viewed as illogically, even pathologically, anxious (Baer, 2023). The lack of critical information literacy demonstrated by many in our own profession regarding COVID-related information is also apparent in the way that we engage with information about autistic people, and I second Baer’s call for information professionals to consider the impact of power and privilege in relation to information literacy.
Fully adopting the neurodiversity paradigm would require that we examine our implicit biases about who is permitted to be an authority on a subject, and how structural inequities have positioned non-autistic experts and their often deficit-based scholarship as the ultimate authority on autistic people. As educators, we have helped students develop an understanding of how issues of power and privilege impact supposedly authoritative information sources in other fields, such as when we note that the majority of medical textbooks have long pictured dermatological conditions on only white skin, significantly impacting physician knowledge and health outcomes for people of color. Just as systemic racism has led to white bodies historically being constructed as the default in medical information, systemic ableism has portrayed non-autistic ways of being as normal, therefore casting autistic and other neurodivergent people in the role of the deviant Other.
It is particularly concerning, and not in alignment with our professional values, that LIS research about autistic college students fails to critically examine the way autistic people have been positioned and continue to be positioned in scholarship, including our own. Embracing the neurodiversity framework would mean addressing our implicit biases about who is a reliable information source about autism, and acknowledging that the mainstream storying of autistic lives has been constructed by professionals with deficit views, marginalizing the voices of autistic participants and scholars (Yergeau, 2018). Though engaging in such reflection and challenging these systems will be uncomfortable, such a shift will make our field safer for autistic participants and colleagues, resulting in more valuable and humanizing research.
Acknowledgements
My sincere thanks to Jessica Schomberg, Kieren Fox, and Ryan Randall for their insightful comments and guidance throughout the publication process – your time and thoughtfulness are much appreciated. Many thanks also to Dr. Kristen Bottema-Beutel, whose feedback and mentorship were invaluable as I drafted this piece.
References
Anderson, A. (2018). Autism and the academic library: A study of online communication. College & Research Libraries, 79(5). https://doi.org/10.5860/crl.79.5.645
Anderson, A. (2021). From mutual awareness to collaboration: Academic libraries and autism support programs. Journal of Librarianship and Information Science, 53(1), 103–115. https://doi.org/10.1177/0961000620918628
Baer, A. (2023). Dominant COVID narratives and implications for information literacy education in the “post-pandemic” United States. In The Library With the Lead Pipe. https://www.inthelibrarywiththeleadpipe.org/2023/covid-narratives/
Bakker, T., Krabbendam, L., Bhulai, S., & Begeer, S. (2019). Background and enrollment characteristics of students with autism from secondary education to higher education. Research in Autism Spectrum Disorders, 67, 1–12. https://doi.org/10.1016/j.rasd.2019.101424
Bernard, S., Doherty, M., Porte, H., Al-Bustani, L., Murphy, L.E., Russel, M.C., & Shaw, S.C.K. (2023). Letter to the editor: Upholding autistic people’s human rights: A neurodiversity toolbox for autism research. Autism Research, 16, 683-684. https://doi.org/10.1002/aur.2907
Botha, M. (2021). Academic, activist, or advocate? Angry, entangled, and emerging: A critical reflection on autism knowledge production. Frontiers in Psychology, 4196.
Botha, M., & Cage, E. (2022). “Autism research is in crisis”: A mixed method study of researcher’s constructions of autistic people and autism research. Frontiers in Psychology, 13, 7397.
Bottema-Beutel, K., Kapp, S.K., Lester, J.N., Sasson, N.J, & Hand, B.N. (2021). Avoiding ableist language: Suggestions for autism researchers. Autism in Adulthood, 3(1), 18-29. http://doi.org/10.1089/aut.2020.0014
Bottema-Beutel, K., Kapp, S.K., Sasson, N., Gernsbacher, M.A., Natri, H., & Botha, M. (2023). Anti-ableism and scientific accuracy in autism research: a false dichotomy. Frontiers in Psychiatry, 14, 1-8. http://doi.org/10.3389/fpsyt.2023.1244451
Boyer, A., & El-Chidiac, A. (2023). Come chill out at the library: Creating soothing spaces for neurodiverse students. Journal of New Librarianship, 8(1), 41–47.
Braumberger, E. (2021). Library services for autistic students in academic libraries: A literature review. Pathfinder: A Canadian Journal for Information Science Students and Early Career Professionals, 2(2), Article 2. https://doi.org/10.29173/pathfinder39
Brunskill, A. (2020). “Without that detail, I’m not coming”: The perspectives of students with disabilities on the accessibility information provided on academic library websites. College & Research Libraries, 81(5), 768-788. https://doi.org/10.5860/crl.81.5.768
Crompton, C. J., Ropar, D., Evans-Williams, C. V., Flynn, E. G., & Fletcher-Watson, S. (2020). Autistic peer-to-peer information transfer is highly effective. Autism, 24(7), 1704-1712.
Everhart, E. & Anderson, A.M. (2020). Research participation and employment for autistic individuals in library and information science: A review of the literature. Library Leadership and Management, 34(3), 1-6. https://doi.org/10.5860/llm.v34i3.7376
Everhart, N., & Anderson, A. (2020). Academic librarians’ support of autistic college students: A quasi-experimental study. The Journal of Academic Librarianship, 46(5), 102225. https://doi.org/10.1016/j.acalib.2020.102225
Everhart, N., & Escobar, K. L. (2018). Conceptualizing the information seeking of college students on the autism spectrum through participant viewpoint ethnography. Library & Information Science Research, 40(3), 269–276. https://doi.org/10.1016/j.lisr.2018.09.009
Lawrence, E. (2013). Loud hands in the library: Neurodiversity in LIS Theory & Practice. Progressive Librarian, 41, 98–109.
Layden, S.J., Anderson, A., & Hayden, K.E. (2021). Are librarians prepared to serve students with autism spectrum disorder? A content analysis of graduate programs. Focus on Autism and Other Developmental Disabilities, 36(3), 156-164. https://doi.org/10.1177/1088357621989254
Lindsay, S., Cagliostro, E., & Carafa, G. (2018). A systematic review of barriers and facilitators of disability disclosure and accommodations for youth in post-secondary education. International Journal of Disability, Development and Education, 65(5), 526–556. https://doi.org/10.1080/1034912X.2018.1430352
Milton, D. E. (2012). On the ontological status of autism: The ‘double empathy problem’. Disability & Society, 27(6), 883-887.
Pionke, J. J., Knight-Davis, S., & Brantley, J. S. (2019). Library involvement in an autism support program: A case study. College & Undergraduate Libraries, 26(3), 221–233. https://doi.org/10.1080/10691316.2019.1668896
Remy, C., Seaman, P., & Polacek, K. M. (2014). Evolving from disability to diversity: How to better serve high-functioning autistic students. Reference & User Services Quarterly, 54(1), 24–28.
Robinson, B., & Anderson, A. M. (2022). Autism training at a small liberal arts college: Librarian perceptions and takeaways. Public Services Quarterly, 18(3), 161–176. https://doi.org/10.1080/15228959.2021.1988808
Shakespeare, T. (200X?). The social model of disability. In L.J. Davis (Ed.) The disability studies reader (4th ed., pp. 214-221). Routledge.
Shea, G., & Derry, S. (2019). Academic libraries and autism spectrum disorder: What do we know? The Journal of Academic Librarianship, 45(4), 326–331. https://doi.org/10.1016/j.acalib.2019.04.007
Sinclair, J. (2013). Why I dislike ‘person first’ language. Autism Network International, 1(2).
Tumlin, Z. (2019). “This is a quiet library, except when it’s not:” On the lack of neurodiversity awareness in librarianship. Music Reference Services Quarterly, 22(1–2), 3–17. https://doi.org/10.1080/10588167.2019.1575017
Walker, N. (2021). Neuroqueer heresies: Notes on the neurodiversity paradigm, autistic empowerment, and postnormal possibilities. Fort Worth, TX: Autonomous Press.
Walton, K., & McMullin, R. (2021). Welcoming autistic students to academic libraries through innovative space utilization. Pennsylvania Libraries: Research & Practice. https://doi.org/10.5195/palrap.2021.259
Yergeau, M.R. (2018). Authoring autism: On rhetoric and neurological queerness. Duke University Press.
In the Library with the Lead Pipe welcomes substantive discussion about the content of published articles. This includes critical feedback. However, comments that are personal attacks or harassment will not be posted. All comments are moderated before posting to ensure that they comply with the Code of Conduct. The editorial board reviews comments on an infrequent schedule (and sometimes WordPress eats comments), so if you have submitted a comment that abides by the Code of Conduct and it hasn’t been posted within a week, please email us at itlwtlp at gmail dot com!
The workshop titled “Empowering Young Changemakers: Utilizing Open Data and Indigenous Knowledge for Climate Action” held on March 2nd, 2024, at the Shamz Hotel boardroom was a resounding success. It provided a pivotal platform for young individuals, driven by their determination to combat the effects of climate change within the pastoralist communities. The event, organized by the Pastoralist Peoples’ Initiative in commemoration of Open Data Day 2024, was a half-day workshop that ran from 9:00 am to 02:30 PM.
The event commenced with an opening address by myself, Mr. Basele Stephen, Director of Programs and Partnerships at the Pastoralist Peoples’ Initiatives. I’m an open data expert with extensive experience in open data protocols, and I’ve been at the forefront of mapping exercises in Northern Kenya with open street maps since 2014. My presentation expounded on the core principles of open data and its potential as a potent tool in the battle against climate change.
In my address, I elaborated on the extensive collection of existing open-source data resources related to climate change and its reporting. This equipped the young changemakers with valuable tools to use in their volunteer work and empowered them with a deeper understanding of the potential impact of open data in their efforts to combat climate change.
The workshop went beyond the realm of open data by emphasizing the crucial role of indigenous communities in preserving traditional knowledge and incorporating it into climate action. Mr. Isaiah Lekesike and Margaret Super shared their invaluable insights on traditional weather forecasting methods and showcased how these time-tested practices can be seamlessly integrated with modern data analysis techniques, demonstrating the potential for young people to bridge the gap between ancestral knowledge and cutting-edge data analysis.
My address also highlighted the disproportionate impact of climate disasters on pastoralist communities, which contribute minimally to environmental pollution but bear the brunt of its consequences. This served as a call to action for the young changemakers to take on the role of climate adaptation leaders within their communities, inspiring them to become active participants in the fight against climate change.
The ensuing discussions were marked by insightful exchanges and engaging dialogues. The challenges faced by young people on the ground, such as limited internet access, scarcity of information specific to Marsabit County, and hurdles in data collection, analysis, and dissemination, were openly discussed. However, the prevailing sentiment was one of unwavering optimism.
Key Takeaways
The workshop yielded several key takeaways that are instrumental in shaping the future endeavours of the young changemakers and their impact on climate action:
Open Data as a Powerful Tool: Understanding and utilizing open data provides young changemakers with valuable insights to address climate challenges within their communities.
The Invaluable Nature of Indigenous Knowledge: Integrating traditional weather forecasting and other practices with modern data analysis can lead to the formulation of more effective climate action strategies.
Collaboration is Paramount: By working together, young people can overcome the challenges of internet access, information scarcity, and data analysis, fostering a spirit of cooperation and collective action.
Empowerment Through Knowledge: Equipping young people with the right tools and knowledge fosters a sense of agency and empowers them to become leaders in climate action within their communities.
Despite the challenges, the dedication and resilience displayed by the young minds gathered at the Hallam Restaurant Boardroom promise a brighter future for Marsabit County and beyond. The workshop served as a source of inspiration, equipping the young changemakers with the knowledge of open data and the wisdom of indigenous practices, empowering them to become catalysts for positive change in their communities.
About Open Data Day
Open Data Day (ODD) is an annual celebration of open data all over the world. Groups from many countries create local events on the day where they will use open data in their communities.
As a way to increase the representation of different cultures, since 2023 we offer the opportunity for organisations to host an Open Data Day event on the best date within a one-week period. In 2024, a total of 287 events happened all over the world between March 2nd-8th, in 60+ countries using 15 different languages.
All outputs are open for everyone to use and re-use.
In 2024, Open Data Day was also a part of the HOT OpenSummit ’23-24 initiative, a creative programme of global event collaborations that leverages experience, passion and connection to drive strong networks and collective action across the humanitarian open mapping movement
For more information, you can reach out to the Open Knowledge Foundation team by emailing opendataday@okfn.org. You can also join the Open Data Day Google Group to ask for advice or share tips and get connected with others.
Nearly every archive is grappling with stewarding born-digital archival collections. Practice and programs supporting born-digital archives continue to evolve as we develop increased understanding of needs and available options to address them. The OCLC Research Library Partnership recently held roundtable discussions with special collections leaders that focused on where our programs are now, how we are leading and resourcing them, and how we hope they might shift and grow in the future.
The discussions were illuminating. Thirty-nine people from 36 RLP institutions in three countries attended one of the sessions. The RLP draws from a unique, international mix of independent, academic, national, and museum libraries, with great variety in size and scale of operations. Even with this range, the consistent story across institutions is that this work is still very much in flux and actively being figured out, often with insufficient resources. Good progress is being made in different areas, but nobody reported satisfaction with their ability to handle all the needs of born-digital collections.
Participants were asked to reflect on the following questions to shape the discussion:
Who has responsibility for born-digital archival collections in your institution? How are you staffing and resourcing support for born-digital collections?
How are you supporting learning and experimentation for the people in these roles?
What are your challenges and where do you need support?
The rest of this post summarizes key takeaways and points of commonality from our discussions.
Digital Archivists
Having a role that takes primary responsibility for born-digital collections — whether a digital archivist, digital preservation librarian or archivist, or something similar— was a key indicator, for many participants, of a mature born-digital records program. While many institutions reported having a digital archivist, a significant number of institutions do not. Those that did varied in the length of time the role had existed, ranging from almost a decade to it being a brand-new position. A handful of institutions have a second, more junior role in addition to a digital archivist, either a digital archives technician or a graduate student worker who handled more routine tasks.
Funding and advocacy for such positions was a commonly cited challenge. The stability of funding for such positions varied, with some institutions getting support for a digital archivist through a grant or other time-limited project funding. Several participants described it as a long game: they were slowly but steadily making the case for a permanent role by articulating the need within strategic planning and prioritization discussions. Turnover was an issue, in both leadership and operational roles. This churn in institutional leadership often meant starting advocacy efforts from scratch. And with digital archivist skills in high demand, retention is a challenge as incumbents are lured to a different institution, resulting in slow progress, and necessitating repeatedly advocating for the need to maintain and refill the role.
Participants also spoke of the need for distributed responsibility across the archives for born-digital collections, whether they had a role with primary responsibility for the work or not. For those at institutions with a defined digital archivist role, they did not feel it was scalable to have one person with sole responsibility for stewarding born-digital and expressed concern about employee burnout. One participant described their desired approach: “We need to ramp up teaching the other staff to help them manage more routine materials, saving weird stuff for the specialists.” Others were intentionally working on a model where born-digital was understood as everybody’s job, in the absence of a digital archivist. Those working within a distributed responsibility framework described a need for better understanding of the competencies required for working with born-digital collections across all archival functions and resources for training staff on these competencies.
Matrixed responsibility
In many large institutions, work on born-digital collections spans multiple departments or units. A surprising number of participants described matrixed organizations where this responsibility sits outside of archives and special collections — sometimes in a shared technical services unit, a digitization or reformatting unit, a digital projects or preservation unit, or in an information technology unit.
Discussion participants spoke of the necessity and challenge of working across departments and functions to advocate for needed infrastructure, especially communicating archives-specific requirements that differ from digital materials collected elsewhere in the library. This was especially true when responsibility for born-digital fell in departments more focused on managing faculty or student research outputs, research data, or digitized content.
Digital preservation
An area where almost all participants seemed to be trying to figure things out was addressing digital preservation needs, from tools for initial identification and ingest to ongoing storage. The resources and/or responsibility for this often fell outside special collections. Several participants were using systems initially funded by grants and now needed to find sustainable support. Others described trying to shoehorn born-digital collections into DAMS or other storage systems that weren’t designed to address the needs of archival collections. Those who have been able to implement digital preservation systems talked about what a positive impact it had on their programs. One participant said, “our lives changed when we were able to move to [System].”
Physical versus digital
An interesting thread that ran through the conversations was the difference between digital and physical collections, and the ways the relative invisibility of digital collections impacted work with them. Much of this centered around advocacy and fundraising. When working with donors who are swayed by interesting and engaging collections, it can be hard to entice them to support something they can’t see. Many talked about the challenge of advocating for digital preservation, storage, and other infrastructural needs. As one participant put it, “You can show administration a physical location. You can show them the boxes…and it looks like something to them. They can conceptualize how much is there and what it is. When you’re in a digital environment, and you’re advocating for your collections, it’s harder. … You [can tell them] the terabyte counts, you can tell them about the collection materials, but it’s harder to conceptualize what those collections look like, or how they’re used or what they are. It takes a more advocacy.”
Participants continue to have difficulty estimating the time needed to appraise, accession, and process born-digital collections, something that is relatively well established with physical collections. The lack of reliable metrics for this work makes advocacy even more challenging.
Access and use
Providing access to born-digital collections was another challenge articulated by many participants. Some institutions provide access via a dedicated workstation or laptop in the reading room. A few are providing online access, including authenticated access to materials that can’t be made available on the open web. But most recounted infrastructure limitations that impacted their ability to provide easy access to digital collections. Several institutions manage access requests on a case-by-case basis, which participants recognize as inefficient and inequitable. Other institutions offer separate delivery tools for born-digital and digitized collections, which they characterize as clunky, bifurcated, and not aligned with how researchers understand and want to discover resources.
Participants also discussed the challenge of incorporating born-digital materials into teaching. One observed that students – who lead digital-first lives — don’t connect with electronic material in the same way they do with physical items.
Curatorial challenges
Participants described multiple ways in which born-digital records impact curatorial work. The most common concern was the volume of records coming in and the challenge of performing appraisal on digital materials. With ever-increasing scale of born-digital collections, the high cost and environmental impacts of storage for those collections, and the front-loaded work required to secure and stabilize them, there is an growing realization that more appraisal work is required before collections are brought in. This challenge is two-fold — the learning curve of working with electronic records coupled with a paradigm shift from appraising physical collections. There is a recognized need to build born-digital appraisal skills among those charged with collection building and to integrate appraisal tools into the pre-acquisition process. Along similar lines, one participant voiced the concern that we are not having enough conversations about how born-digital records are being used, which is leading to uninformed collecting. They went on to say, “it feels like we’re headed for [a] conversation in 20 years about corrective appraisal.”
Several institutions described a lot of investment in born-digital collecting “before we really knew what we were doing,” leading to a significant backlog of collections that need baseline control. That stewardship debt continues to accumulate as they continue to collect. Some archives are declining offers of born-digital collections because of lack of stewardship capacity, describing this as a case-by-case decision. There is anxiety that a “great collection is going to come along, and we’re not going to be in a position to handle it.” Some participants were trying to mitigate past missteps by addressing born-digital in their collection development policy, in some cases putting limitations on what they collect. Others had updated acquisitions procedures and deeds of gift to obtain the permissions they need to serve born-digital to researchers.
Conversely, a move to digital formats is also making it harder to acquire materials that previously arrived in physical form. This was especially true for archives charged with collecting university records or administrative records of their parent organization. Participants explained that senior administrators don’t want to transfer their email; things like electronic newsletters must now be sought out, and in general people don’t seek out transfers to the archives now because they haven’t run out of physical space. “It used to be that people would run out of space in their filing cabinets and call the archives, but those days are over.”
Conclusion
All in all, these were interesting and illuminating conversations that illustrated both how much progress archives have made in working with born-digital collections, and how much work remains. Our evaluations indicated that participants found comfort in learning that they weren’t the only ones struggling to do this work responsibly and to address all the various needs of born-digital. This is a great outcome, as our goal with these roundtables is to bring together library leaders to facilitate peer learning, benchmarking of services, and community building among RLP members. My hope is that the roundtables will continue to provide a space to build community, offer support, and share knowledge.
If you are a member of the RLP and don’t have someone participating in our leadership roundtables, either this one focused on archives and special collections and the other on research support, you can find more information here. Please reach out, we’d love to have you join us.
Hello and happy April, DLF community! It’s spring, and our community is certainly staying busy. We have many exciting group meetings coming up this month, along with some Forum news we’ll be able to share in the coming weeks. Read on to learn how to be a part of all of the great things happening in our world this month. We’ll see you around soon!
Application Remain Open: CLIR invites applications from collecting organizations for the digital reformatting of audio and audiovisual materials for the Recordings at Risk grant program now through April 17, 2024.
Registration Remains Open:Registration is still open for the International Internet Preservation Consortium’s (IIPC) General Assembly and Web Archiving Conference in Paris at the end of this month, April 24-26.
New Publication: The Journal of eScience Librarianship (JeSLIB) and the Responsible AI in Libraries and Archives project have published a Special Issue on Responsible AI in Libraries and Archives; read it here.
This month’s open DLF group meetings:
For the most up-to-date schedule of DLF group meetings and events (plus NDSA meetings, conferences, and more), bookmark the DLF Community Calendar. Can’t find meeting call-in information? Email us at info@diglib.org. Reminder: Team DLF working days are Monday through Thursday.
Born-Digital Access Working Group (BDAWG): Tuesday, April 2, 2pm ET / 11am PT.
Digital Accessibility Working Group (DAWG): Wednesday, April 3, 2pm ET / 11am PT.
Assessment Interest Group (AIG) Cultural Assessment Working Group (CAWG): Monday, April 8, 2pm ET/11am PT.
AIG Cost Assessment Working Group: Monday, April 8, 3pm ET/12pm PT.
AIG Metadata Assessment Working Group: Thursday, April 11, 1:15pm ET / 10:15am PT.
AIG User Experience Working Group: Friday, April 19, 11am ET / 8am PT.
Committee for Equity and Inclusion (CEI): Monday, April 22, 3pm ET / 12pm PT.
Climate Justice Working Group: Wednesday, April 24, 12pm ET / 9am PT.
DAWG Policy & Workflows subgroup: Friday, April 26, 1pm ET / 11am PT.
This month, the Library Innovation Lab celebrated the full and unqualified release of the Caselaw Access Project data. We took the opportunity to gather and look to the future at Transform: Justice on March 8th. The event reminded us of what we already knew: the open legal data movement is alive and well.
In addition to hearing the story of CAP, librarians, vendors, and advocates had conversations about future paths for accessing the law. Noted open-access activist Carl Malamud made his pitch for a Full Faith and Credit Act.
As we see CAP move on to a new chapter, LIL will be bringing the same experimental mindset that allowed for such an ambitious project into other endeavors.
Here’s some of what’s coming up next at the Library Innovation Lab:
Facilitating open, equitable access to knowledge
COLD Cases: We’re excited to be collaborating with the Free Law Project on a couple of projects. First, we worked with FLP to create COLD Cases, a pipeline for standardizing and sharing bulk legal data.
Teraflop & CAP: It’s great to see work by the AI community in processing the CAP dataset for legal understanding, such as this work by Teraflop to generate text embeddings and search indexes for the data.
Future Collaborations: We see potential for Harvard to be a neutral platform for releasing data that helps the whole industry. We are having conversations with companies like Westlaw, LexisNexis, and vLex that see potential in this kind of partnership, and we hope to make more connections soon.
Empower everyone – AI, understanding, access to justice
Open Legal AI Workbench: Our recently released Open Legal AI Workbench is a simple, well-documented, and extensible framework for legal AI researchers to build services using tool-based retrieval augmented generation.
Keep your eyes peeled for more news about the Institutional Data Initiative, a plan to create a trusted conduit for legal data for AI. By pairing high-quality corpora and collection expertise with industry resources, it aims to scale the collaborations between knowledge institutions and industry partners that we discussed at Transform: Justice. The goal is to grow both knowledge and the public interest.
The webinar showcased the extensive geospatial open data collected on the Belvedere Glacier (Italian Alps). This comprehensive dataset was generated through long-term monitoring using innovative UAV and aerial photogrammetry techniques, a collaborative effort between Politecnico di Milano’s DICA department, Politecnico di Torino’s DIIATI department, and the Alta Scuola Politecnica. The event emphasized the value of this open data for research and educational purposes, readily accessible on Zenodo.
Format and Participation
The webinar combined in-person attendance at Politecnico di Milano with online streaming, enabling wider participation.
The event was organized in two modules, as follows:
Module 1: Introduction (~1 hour)
Background on the Belvedere Glacier monitoring and research project
Showcase of the unique Summer School initiative, “Design and Implementation of Topographic Surveys for Territorial Monitoring in Mountain Environments,” serving BSc and MSc students since 2016.
Presentation on the preparation and significance of the long-term Belvedere Glacier monitoring results and the publicly available open data on Zenodo.
Module 2: Hands-on Workshop (~1.5 hours)
In-depth tutorials using open-source software (QGIS and CloudCompare) for DTM and point cloud processing, fostering practical skills.
Approximately 20 participants attended the first module in-person, while 9 people attended both modules on-site. Additional 25 people joined the event online.
“What we think time is, how we think it is shaped, affects how we are able to move through it.”
-Jenny Odell Saving Time, p. 270
This is the first of a series of essays I’ve written on time. Here are the others (they will be linked as they become available on Information Wants to be Free):
Meredith’s Slow Productivity (not to be mistaken for Cal Newport’s Faux Slow Productivity)
Queer Time, Crip Time, and Subverting Temporal Norms
Community Time and Enoughness: The heart of slow librarianship
What I love about reading Jenny Odell’s work is that I often end up with a list of about a dozen other authors I want to look into after I finish her book. She brings such diverse thinkers beautifully into conversation in her work along with her own keen insights and observations. One mention that particularly interested me in Odell’s book Saving Time (2023) was What Can a Body Do(2020) by Sara Hendren. Her book is about how the design of the world around us impacts us, particularly those of us who don’t fit into the narrow band of what is considered “normal,” and how we can build a better world that goes beyond accommodation. Her book begins with the question “Who is the built world built for?” and with a quote from Albert Camus: “But one day the ‘why’ arises, and everything begins in that weariness tinged with amazement” (1).
“Why” is such a simple world, but asking it can completely alter the way we see the world. There’s so much in our world that we simply take for granted or assume is the only way because some ideology (like neoliberalism) has so deeply limited the scope of our imagination. Most of what exists in our world is based on some sort of ideological bias and when we ask “why” we crack the world open and allow in other possibilities. Before I read the book Invisible Women (2021) by Caroline Criado Perez, I already knew that there was a bias towards men in research and data collection as in most things, but I didn’t realize the extent to which the world was designed as if men were the only people who inhabited it and how dangerous and harmful it makes the world for women. What Can a Body Do similarly begins with an exploration of the construction of “normal” and how design based on that imagined normal person can exclude and harm people who aren’t considered normal, particularly those with disabilities. The book is a wonderful companion to Invisible Women in looking at why the world is designed the way it is and how it impacts those who it clearly was not built for. I’ll explore that more in a later essay in this series.
One thing I took for granted for a very long time was time itself. I thought of time in terms of clocks and calendars, not the rhythms of my body nor the seasons (unless you count the start and end of each academic term as a season). I believed that time was scarce, that we were meant to use it to do valuable things, and that anything less was a waste of our precious time. I would beat myself up when, over Spring Break, I didn’t get enough practical home or scholarship projects done or if I didn’t knock everything off my to-do list at the end of a work week. I would feel angry and frustrated with myself when my bodily needs got in the way of getting things done (I’m writing this with ice on both knees due to a totally random flare of tendinitis when I’d planned to do a major house cleaning today so I’m really glad I don’t fall into that shooting myself with the second arrow trap as much as I used to). I looked for ways to use my time more efficiently. I am embarrassed to admit that I owned a copy of David Allen’s Getting Things Done and tried a variety of different time management methods over the years that colleagues and friends recommended (though nothing ever stuck besides a boring, traditional running to-do list). I’d often let work bleed into home time so I could wrap up a project because not finishing it would weigh on my mind. I was always dogged by the idea that I wasn’t getting enough done and that I could be doing things more efficiently. It felt like there was never enough time all the time.
From Harold Lloyd’s Safety Last (1923)
I didn’t start asking questions about time until I was 40 and the first one I asked was a big one “what is the point of our lives?” Thinking about that opened a whole world of other questions about how we conceive of time, what kinds of time we value, to what end are we constantly trying to optimize ourselves, what is considered productive vs. unproductive time, why we often value work time over personal time (if not in word then in deed), why time often requires disembodiment, etc. The questions tumbled out of me like dominoes falling. And with each question, I could see more and more that the possibility exists to have a different, a better, relationship with time. I feel Camus’ “weariness, tinged with amazement.”
This is an introduction to a series of essays about time: how we conceive of it, how it drives our actions, perceptions, and feelings, and how we might approach time differently. I’ll be pulling ideas for alternative views of time from a few different areas, particularly queer theory, disability studies, and the slow movement. I’m not an expert in all these areas, but I’ll be sure to point you to people more knowledgeable than me if you want to explore these ideas in more depth.
How many of you feel overloaded with work? Like you’re not getting enough done? How many of you are experiencing time poverty: where your to-do list is longer than the time you have to do your work? How many of you feel constantly distracted and/or forced to frequently task-switch in order to be seen as a good employee? How many of you feel like you’re expected to do or be expert in more than ever in your role? How many of you feel like it’s your fault when you struggle to keep up? More of us are experiencing burnout than ever before and yet we keep going down this road of time acceleration, constant growth, and continuous availability that is causing us real harm. People on the whole are not working that many more hours than they used to, but we are experiencing time poverty and time compression like never before, and that feeling bleeds into every other area of our lives. If you want to read more about how this is impacting library workers, I’ll have a few article recommendations at the end of this essay.
My exploration is driven largely by this statement from sociologist Judy Wajcman’s (2014) excellent book Pressed for Time: “How we use our time is fundamentally affected by the temporal parameters of work. Yet there is nothing natural or inevitable about the way we work” (166). We have fallen into the trap of believing that the way we work now is the only way we can work. We have fallen into the trap of centering work temporality in our lives. And we help cement this as the only possible reality every time we choose to go along with temporal norms that are causing us harm. In my next essay, I’m going to explore how time became centered around work and how problematic it is that we never have a definition of what it would look like to be doing enough. From there, I’m going to look at alternative views of time that might open up possibilities for changing what time is centered around and seeing our time as more embodied and more interdependent. My ideas are not the be-all end-all and I’m sure there are thinkers and theories I’ve not yet encountered that would open up even more the possibilities for new relationships with time. To that end, I’d love to get your thoughts on these topics, your reading recommendations, and your ideas for possible alternative futures in how we conceive of and use time.
Works on Time in Libraries
Bossaller, Jenny, Christopher Sean Burns, and Amy VanScoy. “Re-conceiving time in reference and information services work: a qualitative secondary analysis.” Journal of Documentation 73, no. 1 (2017): 2-17.
Brons, Adena, Chloe Riley, Ean Henninger, and Crystal Yin. “Precarity Doesn’t Care: Precarious Employment as a Dysfunctional Practice in Libraries.” (2022).
Drabinski, Emily. “A kairos of the critical: Teaching critically in a time of compliance.” Communications in Information Literacy 11, no. 1 (2017): 2.
Kendrick, Kaetrena Davis. “The public librarian low-morale experience: A qualitative study.” Partnership 15, no. 2 (2020): 1-32.
Kendrick, Kaetrena Davis and Ione T. Damasco. “Low morale in ethnic and racial minority academic librarians: An experiential study.” Library Trends 68, no. 2 (2019): 174-212.
Lennertz, Lora L. and Phillip J. Jones. “A question of time: Sociotemporality in academic libraries.” College & Research Libraries 81, no. 4 (2020): 701.
McKenzie, Pamela J., and Elisabeth Davies. “Documenting multiple temporalities.” Journal of Documentation 78, no. 1 (2022): 38-59.
Mitchell, Carmen, Lauren Magnuson, and Holly Hampton. “Please Scream Inside Your Heart: How a Global Pandemic Affected Burnout in an Academic Library.” Journal of Radical Librarianship 9 (2023): 159-179.
Nicholson, Karen P. “Being in Time”: New Public Management, Academic Librarians, and the Temporal Labor of Pink-Collar Public Service Work.” Library Trends 68, no. 2 (2019): 130-152.
Nicholson, Karen. “On the space/time of information literacy, higher education, and the global knowledge economy.” Journal of Critical Library and Information Studies 2, no. 1 (2019).
Nicholson, Karen P. ““Taking back” information literacy: Time and the one-shot in the neoliberal university.” In Critical library pedagogy handbook (vol. 1), ed. Nicole Pagowsky and Kelly McElroy (Chicago: ACRL, 2016), 25-39.
Awesome Works on Time Cited Here
Hendren, Sara. What Can a Body Do?: How We Meet the Built World. Penguin, 2020.
Odell, Jenny. Saving Time: Discovering a Life Beyond Productivity Culture. Random House, 2023.
Wajcman, Judy. Pressed for time: The acceleration of life in digital capitalism. University of Chicago Press, 2020.
Once upon a time, people lived more by the natural rhythms of seasons, the movement of the sun, and their bodies. There weren’t clocks to tell them when to do things and there wasn’t electric light and heat to make it easy to pretend it’s normal to work in the dark (burning the midnight oil used to be a real thing, and wasteful!). People didn’t live by precise times and society didn’t require the sort of coordination and standardization we have today. We’ve lived so long with clocks, it can be hard to imagine waking with the sun rather than at a specific appointed number on a clock every day. Clock time might even feel to us a more objective measure of time because it’s what we’ve used all our lives to determine our waking and sleeping, our work time and leisure, and our times to eat and exercise. In reality, it’s the most contrived measure of time, one deeply encumbered by social values and largely designed around economic needs.
Precision and coordination in measuring time was first used by monks to ensure they were adhering to the proper times for prayer, but even those times often differed depending on the time of year (the position of the sun). It wasn’t until Huygens developed the pendulum clock that clock time came into wider use, but this was also the moment of the birth of industry, which required time discipline, the “high degrees of standardization and regularity and coordination” of people’s time (Glennie & Thrift 1996, 287). E. P. Thompson, who wrote the seminal work on the growth of clock time in early modern Britain, writes about how quickly clock time and time as a commodity became the only ways of conceiving of time:
The first generation of factory workers were taught by their masters the importance of time; the second generation formed their short-time committees in the ten-hour movement; the third generation struck for overtime or time-and-a-half. They had accepted the categories of their employers and learned to fight back within them. They had learned their lesson, that time is money, only too well.
-E. P. Thompson 1967, 86
Even in that early-modern era, there wasn’t the sort of standardization of time we see today. The idea of standard times and time zones are a 19th Century invention that wasn’t fully adopted by the entire world well into the 20th Century. Localities used to have their own time — originally determined by the movement of the sun — which was not a problem until the growth of fast transportation and communication technologies made those local differences more glaring and inconvenient. Eventually, Greenwich Mean Time became the standard all were forced to follow, though even now, the main tower clock in Bristol, England has a third hand that denotes their original local time. Like so many things that stand in opposition to nature, clock time became a tool of oppression: “the Western separation of clock time from the rhythms of nature helped imperialists establish superiority over other cultures” (Zadeh). Barbara Adam (2002), who has written brilliantly on the sociology of time, rightly brings up the fact that those natural rhythms did not cease to exist with the invention of clock time: “Yet clock time has not replaced the multiple social, biological, and physical sources of time; it has rather changed the meanings of the variable times, temporalities, timings, and tempos of bio-cultural origin… Machine time has been reified to a point at which we have lost touch with other rhythms and with the multiple times of our existence” (513-14).
At the same time that this was happening, Protestantism was preaching time discipline, with leisure seen as an affront to God, and labor “serve[ed] to increase the glory of God, according to the definite manifestations of His will” (Weber Ch. 5). According to Max Weber, this Protestant ethic has become fully secularized over time, though the fervor behind people’s sense of vocation and the importance of money-making beyond real need still feels almost religious in its fervor:
If you ask them what is the meaning of their restless activity, why they are never satisfied with what they have, thus appearing so senseless to any purely worldly view of life, they would perhaps give the answer, if they know any at all: “to provide for my children and grandchildren.” But more often and, since that motive is not peculiar to them, but was just as effective for the traditionalist, more correctly, simply: that business with its continuous work has become a necessary part of their lives. That is in fact the only possible motivation, but it at the same time expresses what is, seen from the viewpoint of personal happiness, so irrational about this sort of life, where a man exists for the sake of his business, instead of the reverse.
-Max Weber, ch 2.
These forces all helped to place work time at the center of our lives and cement the notion of time as money; two things that have only been further entrenched in our contemporary neoliberal society. Time discipline was originally enforced by managers, but we have seen “a movement away from an outer, visible coercion toward an inner regulation administered by the individual himself” (Rosengren 2019, 622). We are driven to reproduce time discipline ourselves, more by virtue of our own sense of precarity (whether because of the nature of our job, our internal insecurity, or both) and individualistic desire to rise than by specific discipline from a manager.
Luckily, some of us are starting to question what is behind all this. While business leaders were promoting the idea of quiet quitting as a dereliction of duty, most of us could clearly see that what they were describing as “quiet quitting” was “just doing your job.” We’ve been so conditioned to see going above and beyond as the minimum expectation that the idea of doing just what is required of us was seen as tantamount to quitting.
I’ve been working in libraries for 20 years at this point and I’ve felt over the past thirteen years more overburdened and exhausted than I did in the preceding seven. The pace of work feels like it’s accelerating. And I could assume that it’s just me and aging and the fact that I’ve been a parent for all of those latter years, but the literature suggests that this goes far beyond my individual experience. We’re being asked to do more than ever before. As a liaison librarian, I remember reading New Roles for New Times a decade ago and thinking how difficult it would be to develop expertise in all of the listed areas. Since then, we’ve been asked to become experts in even more, like AI, algorithmic bias, open educational resources, and more. And we’re also subject to more interruptions than ever before (as Lennertz and Jones; Bossaller, Burns, and VanScoy; and Nicholson all highlight). Bossaller, Burns and VanScoy (2017) found that the librarians they interviewed “experienced time famine, time pressure, time poverty, and time fatigue” (15). Even if you’re not working more hours, the feeling that you can never catch up, that you’re drowning in to-do’s can have a significantly negative impact on your mental health and relationships (Giurge, Whillans, and West 2020).
I’ve seen the argument made that since people aren’t actually working that much more than they did 30 years ago, this stress is of their own creation, but I take that claim about as seriously as the claim that people just aren’t as “resilient” as they used to be. There are systemic changes that some are trying to frame as individual changes to get us to grind harder. I’ve written in the past about the normalization of overwork and Brons, et al. (2022) have written about how precarity helps to further entrench overwork as the norm. Mazzetti, Schaufeli, & Guglielmi (2014) demonstrated that while there might be personality characteristics common to workaholics, the greatest determinant of overwork is the organizational climate. When overwork is seen as the minimum expectation and it is rewarded with promotions and raises, it becomes the base expectation. Yet the research on the negative long-term effects of overwork is unequivocal:
Overwork refers specifically to the cumulative consequences of operating at ‘‘overcapacity.’’ Additional hours spent at work eventually creates fatigue or stress so that the worker’s physical or mental health, well-being, health, or quality of life is not sustainable in the longer run. Adverse effects of excess work on various indicators of worker’s well-being from individuals and families to employers and the (national or global) economy have been fairly well established empirically.
-Golden & Altman, 65
Our organizations are short-sightedly running their employees into burnout or worse when a sustainable pace would likely provide better long-term outcomes for the organization (and the individual!).
Urgency is also a huge part of the timescape of libraries. Lennertz and Jones (2020) write about a study that “found greater urgency in the university than the factory” which surprises me not at all. I think that’s become true of a lot of knowledge work-type jobs. I’ve seen libraries go through multiple overlapping cycles of “crisis” and what Meyers et al. (2021) refer to as “the exceptional present” in order to create urgency and pressure us to overwork. Because when there’s a crisis, we all need to step up and do our part. But what if we’re just in a constant state of crisis? It seems like there’s always another reason to step up and do more and its treated like a temporary blip. I remember for years at the past two libraries I worked with, we kept putting off major departmental planning until things settled down because we felt we were always in reaction mode. But things never settled down at either library. And being in a constant state of crisis and urgency eventually wears you out and numbs you. We can’t operate in reactive mode forever; it’s just not healthy for us as individuals or for the organization. It makes thoughtful and inclusive planning impossible. And urgency has been called out as being a characteristic of white supremacy culture.
There’s also this feeling that we need to keep growing and building limitlessly; there’s no vision for what enough might actually look like. I remember years ago when I first became an instruction head, my boss asked me to have as an annual goal to increase instruction sessions by 25%. A daunting task, right? Well, through quite a lot of outreach and the generosity of my fellow instruction librarians, we actually met that goal! Woo hoo! But to my surprise, my boss wanted me to put the exact same metric into my goals for the following year. This time I objected. The first reason was because we had a lot of folks who were new to or were uncomfortable with teaching and it made a lot more sense to focus that year on the quality of our teaching than the quantity (because who cares that you’re teaching a lot if your teaching is not effective? We’re not made of magic). But her request also made me wonder at what point would we be teaching enough? What was the magic number? Would I be expected to increase the number of classes we taught endlessly? And how would we manage all that teaching (and outreach!) with already full workloads? Our profession is incredibly bad at defining what enough looks like and I think it’s a key reason why we constantly add new projects and services without considering long-term sustainability. We feel like we have to constantly do more and new things to prove our worth, and the worth of the library, and it’s an exhausting treadmill we could run on forever.
We talk a lot in libraries about work-life balance, but I’ve come to believe a balance is really impossible if work is always treated as more important than life. Work time dominates and shapes the rest of our time, impacting our wellness and our relationships. Arlie Russell Hochschild (1997) documented how work time encroaches on family and leisure time in her ethnographic research: “the more its deadlines, its cycles, its pauses and interruptions shape our lives and the more family time is forced to accommodate to the pressures of work” (45). When we are at home, work interruptions (like a quick email or something) are considered no big deal these days, but we’re expected when we’re at work to be 100% focused on work and pretend that we don’t have bodies, caregiving responsibilities, and worries in our lives. We’re expected to shut those parts of ourselves off. But how many times have you checked work email before you’ve gone to work or on the weekend “just in case?” It’s become totally acceptable for work to encroach on our personal lives, but not the other way around. We take pains to keep our lives from spilling into our work.
I remember when I had a baby and experienced the absurdity of being expected to suddenly show up back at work and do exactly as much as I did before. I was suffering from postpartum depression and both my son and I were dealing with one health issue after another, but the message coming from work and society was that if I wasn’t just as productive as I’d been pre-baby, I was a failure. I didn’t feel like I could ask for help at work because we’re socialized to see that as weakness and asking for preferential treatment. I felt pressure to be perfect at home lest I make some minor mistake that harmed my child’s entire future (the mommy message boards were full of fear-mongering) and to also prove that I could still do all my work, speak at conferences, write book chapters and articles, and do everything at just as high a level as I ever did. It almost killed me. And I truly believe that our culture pushes caregivers to pursue a level of perfection that is unsustainable. I identified so much with this quote from Mitchell, Magnusen, and Hampton’s (2023) autoethnography about burnout:
I knew that being a single mother made me a liability – at least in a world where capitalism is valued over having an actual life. I say this because in my experience, in academic spaces, it was expected that all employees leave our personal lives at the door. We were strictly meant to focus on work and not concern ourselves with our personal lives once we were on the clock. (166)
We live and work in a society that believes we shouldn’t have bodies, loved ones, or needs outside of the workplace at any time while we’re working. Stuffing those things down while we’re at our jobs tends only to exacerbate those issues. As someone who taught and worked reference shifts with migraines, I can attest that muscling through the pain only made it more difficult to get rid of the migraine once I got back home. I once ended up spending over $1000 and a whole summer in physical therapy (and pain) because I ignored the harm my desk chair was causing me and kept sitting in it for work despite the growing pain in my hips. Yet I blithely let work bleed into my personal life without a second thought and gave so many hours of my personal time to work without thinking about the cost to my well-being and that of my loved ones.
I’m going to write more about things that push us out of sync with work temporality (disability, caregiving, etc.) and more embodied and interdependent ways to be at work in a future essay in this series. We can’t just be floating brains at work with no encumbrances; what makes us great at our jobs is everything that makes us who we are. We are whole people and deserve to be valued for our wholeness. We need to stop punishing people (whether explicitly or through the cultural norms we’ve created) for having needs that may sometimes interfere with work.
Some might counter with the fact that we have more flexibility at work than ever. Some of us can work from home. Some of us can flex our time to be at our child’s play or our loved one’s medical appointment. We can often work from anywhere we have an internet connection. Workplace flexibility has been touted as being beneficial for workers (especially caregivers and those with illnesses or disabilities), but is usually gamed to benefit the employer. Golden and Altman (2006) and Anttila, et al. (2015) found that workers with more flexibility tend to work longer hours. I’ve certainly seen it myself where those who take advantage of flexible hours to accommodate caregiving needs feel obligated to prove their worthiness by working even more. It’s like how so many child-bearing academics are afraid of accepting a tenure clock extension because they fear they will be seen as weak or their tenure packet judged more harshly (and in many cases, they are). I’d imagine that those who do accept the extension feel enormous pressure to prove that they are even more productive as those who do not have such a gap in their CVs.
Flexibility and our 24/7 culture combine to create an expectation of constant availability. And the flex tends to be toward work, not toward the needs in our personal lives. We stay late, we check work email at night or when we first wake up in the morning, we do work on our laptops while watching TV with the family and pretend that it’s quality time. Lennertz and Jones (2020) found that the vast majority of library workers have had to do work during vacations, which is patently absurd in a profession where no one is going to die due to our lack of availability. Bourne and Forman (2014) suggest that flexibility won’t help fix work-life balance issues as long as our society continues to value work time and devalue what we do outside of work.
Nothing will materially change until we 1) change the calculus where work is seen as more important than anything else in our lives and 2) resist norms around overwork, availability, and response times. And really, it has to be those of us with the most privilege and job security to fight the hardest to change these norms in our organizations because those working in precarity will not have the safety to do so outside of a union (and even then, it can be risky in some orgs). Every time we check our email outside of work hours, every time we “just finish this up” when we’re supposed to be spending time with loved ones, every time we overwork, we are helping to reproduce the existing norms. I’ve written in the past about uncoupling our sense of worth from our work identity and achievements and I think that’s an important first step toward changing work’s dominant place in our lives. But it’s going to require real collective action and solidarity to change the norms, especially when there’s always the promise that if you, as an individual, work harder, you will be rewarded. This monstrous treadmill will never stop unless we stand together.
What you contribute to work is not the measure of your worth. And it’s certainly not more important than you or the people you love. Can you imagine how things might look different if work were not centered?
Adam, Barbara. “Perceptions of time.” In Companion encyclopedia of anthropology, ed. Tim Ingold pp. 503-526. Routledge, 2002.
Anttila, Timo, Tomi Oinas, Mia Tammelin, and Jouko Nätti. “Working-time regimes and work-life balance in Europe.” European Sociological Review 31, no. 6 (2015): 713-724.
Bourne, Kristina A., and Pamela J. Forman. “Living in a culture of overwork: An ethnographic study of flexibility.” Journal of Management Inquiry 23, no. 1 (2014): 68-79.
Bossaller, Jenny, Christopher Sean Burns, and Amy VanScoy. “Re-conceiving time in reference and information services work: a qualitative secondary analysis.” Journal of Documentation 73, no. 1 (2017): 2-17.
Brons, Adena, Chloe Riley, Ean Henninger, and Crystal Yin. “Precarity Doesn’t Care: Precarious Employment as a Dysfunctional Practice in Libraries.” (2022).
Glennie, P. and Thrift, N., 1996. Reworking EP Thompson’sTime, work-discipline and industrial capitalism’. Time & Society, 5(3), pp.275-299.
Giurge, Laura M., Ashley V. Whillans, and Colin West. “Why time poverty matters for individuals, organisations and nations.” Nature Human Behaviour 4, no. 10 (2020): 993-1003.
Golden, Lonnie and Morris Altman. “How long? The historical, economic and cultural factors behind working hours and overwork.” Research companion to working time and work addiction Ed. Ronald J. Burke, Edward Elgar Publishing (2006): 36-57.
Hochschild, Arlie Russell. 1997. The Time Bind : When Work Becomes Home and Home Becomes Work. 1st ed. New York: Metropolitan Books.
Lennertz, Lora L. and Phillip J. Jones. “A question of time: Sociotemporality in academic libraries.” College & Research Libraries 81, no. 4 (2020): 701.
Mazzetti, Greta, Wilmar B. Schaufeli, and Dina Guglielmi. “Are workaholics born or made? Relations of workaholism with person characteristics and overwork climate.” International Journal of Stress Management 21, no. 3 (2014): 227.
Meyers, Natalie K., Anna Michelle Martinez-Montavon, Mikala Narlock, and Kim Stathers. “A Genealogy of Refusal: Walking Away from Crisis and Scarcity Narratives.” Canadian Journal of Academic Librarianship 7 (2021): 1-18.
Mitchell, Carmen, Lauren Magnuson, and Holly Hampton. “Please Scream Inside Your Heart: How a Global Pandemic Affected Burnout in an Academic Library.” Journal of Radical Librarianship 9 (2023): 159-179.
Nicholson, Karen P. “Being in Time”: New Public Management, Academic Librarians, and the Temporal Labor of Pink-Collar Public Service Work.” Library Trends 68, no. 2 (2019): 130-152.
Rosengren, Calle. “Performing work: The drama of everyday working life.” Time & Society 28, no. 2 (2019): 613-633.
Thompson, E. P. “Time, Work-Discipline, and Industrial Capitalism.” Past & Present 38 (1967): 56-97.
Weber, Max. 2001 [1930]. The Protestant Ethic and the Spirit of Capitalism. New York, NY: Routledge.
Zadeh, Joe. “The Tyranny of Time.” NOĒMA, (3 June 2021) www.noemamag.com/the-tyranny-of-time/.
In commemorating Open Data Day 2024, we, the UP Resilience Institute YouthMappers (UPRIYM) embraced a vision recognizing biking communities as integral yet vulnerable segments within the urban landscape. Constantly navigating streets shared with motorized vehicles, these communities face the daily struggle for equitable space allocation, advocating for their right to safe and accessible routes. Simultaneously, they embody a passion for bi-modal transportation, championing the versatility of folding bikes as a sustainable alternative. Recognizing their unique position at the intersection of activism and recreation, we sought innovative ways to engage with these communities, harnessing their inherent enthusiasm to drive positive change.
By partnering with biking communities such as the Tiklop Society of the Philippines (TSP), we seized the opportunity to celebrate this year’s Open Data Day by launching Pedal Map, a project to engage biking communities with open mapping for Sustainable Development Goals. This project is a tailored approach that directly addresses their interests and concerns.
Official poster announcing the partnership between UPRIYM and TSP
Understanding the transformative potential of open data in shaping urban environments, we collaborated with TSP to facilitate a workshop and conduct a short field session to demystify the open data concept and elucidate its relevance to their daily experiences. Through a session on Mapillary, a platform for street-level imagery collection for OpenStreetMap, bikers were empowered with the knowledge and tools to actively contribute to creating more inclusive and accurate mapping solutions, leveraging their unique perspectives as frequent users of urban thoroughfares.
With a team of 15 dedicated bikers, we traversed the streets of UP Diliman, armed with cameras through their smartphones and a shared vision of enhancing open data accessibility. Through our collective efforts, we contributed over 2,000 images to Mapillary, bridging crucial gaps in our urban landscape’s visual representation through OpenStreetMap.
Tiklop Society of the Philippines (TSP) and UPRI YouthMappers before deploying for the short field sessionStreet-level images in Village A (UP Diliman) uploaded at Mapillary
The impact of our collaborative endeavor promises to be profound, fostering a deeper understanding of our surroundings and empowering communities through accessible, open data. Furthermore, our engagement with biking communities extended beyond direct participation in data collection activities to encompass broader advocacy efforts to foster a culture of data literacy and civic engagement. By integrating open data principles into their advocacy initiatives, bikers were equipped to amplify their voices and advocate for infrastructure improvements that prioritize the needs of non-motorized road users. Through this multifaceted approach, we celebrated Open Data Day and cultivated lasting partnerships with targeted communities, catalyzing both direct and indirect impacts on urban mobility and accessibility.
As we reflect on this enriching experience, we eagerly anticipate future partnerships with the Tiklop Society of the Philippines, recognizing the invaluable role of grassroots initiatives in driving positive change.
Our heartfelt gratitude extends to the Open Knowledge Foundation (OKFN) and the Humanitarian OpenStreetMap Team (HOT) for their unwavering support and sponsorship, underscoring the significance of collaborative networks in advancing the global open data movement.
We reaffirm the belief that we are truly #BetterTogetherThanAlone. Through collective action, we can harness the transformative power of open data to build a more sustainable and inclusive future for all.
The Library Innovation Lab is excited to announce that the original limitations on the data available for the Caselaw Access Project expired this month, and that data can now be fully released without restriction on access or use.
As part of our original collaboration agreement with Ravel Law, Inc. (now part of LexisNexis) for the Caselaw Access Project there had been access limitations on the full text and bulk data available, which have now expired. Over the next few months, we will be partnering with other organizations in the open legal data space like the Free Law Project to shepherd this data into its next phase. The Free Law Project already includes all CAP cases, as well as cases scraped from court websites, in its CourtListener search engine.
We will continue hosting the CAP data in bulk for researchers, and as individual readable cases, at case.law. However, we will be winding down services that can be better provided elsewhere, such as the search function and API.
The previous version of the site will still be available at old.case.law until September of this year. If there are features of the previous site that are not well covered by the current site or by CourtListener, we welcome feedback to info@case.law.
This transition will allow new avenues for users to access the data produced by the Caselaw Access Project, and will consolidate efforts to create centralized access points for the law. We are very proud of the contribution that CAP has made to the open legal data movement, and will continue working to expand and support free, open, and fair access to information.
History of the Caselaw Access Project
In 2018, the Library Innovation Lab launched case.law to host and distribute data created by the Caselaw Access Project. Its release was the culmination of several years of work at the Harvard Law Library to digitize a corpus of 6 million cases representing almost all precedential law in the United States. The cases were digitized from Harvard’s own collection of hardbound court reporters from across the nation, an archive which predates the founding of the United States. The digitization process involved removing the binding of each volume, scanning 40 million pages, and using OCR technology to convert the PDF images into human and machine-readable text. You can see parts of that process in this video we released about the project.
Though most government documents are in the public domain, including case law, this scope of United States case law had never before been made easily accessible to the public.
Since 2023, we are meeting with more than 100 people to discuss the future of open knowledge, shaped by a diverse set of visions from artists, activists, scholars, archivists, thinkers, policymakers, data scientists, educators, and community leaders from everywhere.
The Open Knowledge Foundation team wants to identify and discuss issues sensitive to our movement and use this effort to constantly shape our actions and business strategies to deliver best what the community expects of us and our network, a pioneering organisation that has been defining the standards of the open movement for two decades.
Another goal is to include the perspectives of people of diverse backgrounds, especially those from marginalised communities, dissident identities, and whose geographic location is outside of the world’s major financial powers.
How openness can accelerate and strengthen the struggles against the complex challenges of our time? This is the key question behind conversations like the one you can read below.
*
This week we had the opportunity to speak with Angela Oduor Lungati, Executive Director of Ushahidi, a global not-for-profit technology company based in Nairobi, Kenya, that helps communities collect and share information.
Angela is a technologist, community builder and open-source software advocate who is passionate about building and using appropriate technology tools to create an impact in the lives of marginalized groups. She has over 10 years’ experience in software development, global community engagement, and nonprofit organizational management. She is also a co-founder of AkiraChix, a non-profit organization that nurtures generations of women who use technology to develop innovations and solutions for Africa.
This conversation took place online on 12 March 2024 and was moderated by Renata Ávila, CEO of OKFN, and Lucas Pretti, OKFN’s Communications & Advocacy Director.
We hope you enjoy reading it.
*
Renata Ávila: One of the memories of the early days of the open movement is how strongly it rallied around a positive agenda, rather than just opposing everything. It was this spirit of “I can do it myself”. If I’ve got a computer at home, access to the internet and some skills, I’ll do it. Looking back so many years later, I define them as very privileged compared to so many people who didn’t have those resources. I wanted to do this little introduction to ask you to tell me the story of Ushahidi. How was it born? How long ago?
Angela Oduor Lungati: Ushahidi is a Swahili word that means testimony. The company was born out of a very dark time in Kenya’s history. The background is the 2007 elections. There were some really strong tribal tensions, a lot of mistrust and people were very resistant to the election results if they weren’t the winners. So when the results were announced, violence broke out in all parts of the country. One of the main problems at the time, apart from the violence itself, was that there was a nationwide media blackout. This meant that not everyone in the country was fully aware of the extent of the situation because the media wasn’t able to cover it. There was a huge information vacuum, whether it was for people living in Kenya at the time or people in the diaspora who were worried about their families and the country.
So a group of five Kenyan bloggers got together and decided to find a way to let the world know what was happening. It was a way of bearing witness, sharing testimony. A platform was set up very quickly and people were able to share news of what was happening around them. It could be the riots, or information about people invading a particular place, or the opposite, reports of a largely peaceful area. All very easily via text message, email or Twitter. This information would be pulled into the platform and then visualised on a map. In this first instance of Ushahidi, it was possible to get a very quick visual representation of the pockets of violence in each region and a very quick situational awareness of how deep the problem was.
It’s a context that’s probably common to a lot of other African countries: bad governance and low bandwidth at a time when social platforms were emerging and people could be a bit more vocal about their opinions. So the founders of Ushahidi were able to build a tool that changed the way information flows, because it wasn’t trickling down from official sources, it was more of a bottom-up approach.
They quickly realised that a tool built for this kind of situation could be useful in other places. How can we make it easier for people to replicate this? And that’s the origin story of making the Ushahidi platform open source, making sure that it was easy to download or that people could sign up and get it up and running quickly. Something similar for them to be able to engage with disenfranchised communities and see how they can come together to be part of the solution rather than passive recipients of information.
Renata Ávila: How did Ushahidi develop after that initial spark?
Angela Oduor Lungati: Over the last 16 years, Ushahidi has been used in several categories of social impact. The main one is crisis response. If you think about the Kenyan elections, the Haiti earthquake, the Nepal earthquake, COVID-19, etc., the platform is a very good way to engage with people affected by crises and then have that feedback directly influence humanitarian response and human rights protection.
One of my favourite examples is HarassMap in Egypt. They started by just documenting cases of sexual harassment of women in Egypt. Over time, they built a model that has inspired 20 other different harassmaps around the world. With this initiative, people are not only collecting data and raising awareness, but also thinking about how to use data to influence behavioural and political change.
In Kenya, we’ve used Ushahidi in every single election since 2007. In 2010, during the constitutional referendum, the general elections in 2013, 2017, and 2022. Nigeria communities have also used it extensively. I know it’s also been used in the US and many other spaces. More recently, we’ve been reaching disenfranchised communities to centre the citizen voice in the conversation around climate change.
Renata Ávila: In the beginning, openness was a very technical thing, basically referring to rules in the boundaries of mainstream systems. Open code and open licences, for example, refer to restrictions on the ability to share. So activists were dedicated to opening little windows and cracks in the system to allow better sharing. I’d like to explore the different perspectives of openness today and the different degrees of openness – like the community aspect, participation, governance and accessibility. What role do these elements play in keeping Ushahidi going?
Angela Oduor Lungati: Before I get into the context of Ushahidi, I want to answer this from a conceptual perspective. If you don’t have a community around a tool that you’re trying to make open, that might be a sign that there’s a challenge to openness. A classic example is, if you don’t have people contributing to your code, you start to wonder, is there a challenge with them installing the software? With them understanding how to contribute? With the language that they’re interacting with? I think a great indicator of openness might actually be the size and health of your community. That could tell you how open you are.
If you think about it in the context of Ushahidi, from the moment we open-sourced the platform, the founders were very intentional about being inclusive. We wanted to make sure that anyone who needed the tool could use it, by lowering the barriers. In a time of crisis, there are people who do not have the technical skills or resources to set up a self-hosted instance and keep the technical infrastructure running smoothly.
One of our strategies was to focus the developments on the mobile aspect, that was the lowest hanging fruit to make sure that people could be involved. Mobile phones are the most ubiquitous device, even my grandmother will have one, whether she has access to the internet or not. Another strategy was to recognise that not everyone in the world speaks English. So the logic is, how do we make it easy for people to interact with the tool in a way that they already can? And then, most importantly, how do we facilitate the connection between people to ensure that they can share their learning with each other. If somebody in Kenya is doing an election project and they learn something from it, how do they share that with somebody else in Nigeria, or somebody else in Congo, somebody else in Zambia, so that they can pick it up and build on it and build on it. A lot of the growth we’ve seen has come from making sure that there are structures in place that invite people to participate.
Over time, of course, and this isn’t just Ushahidi, it’s many other non-profits, we’ve had to think about how to sustain this and keep the lights on. That is the sustainability aspect of openness. There’s been quite a bit of friction between the need for openness and maintaining an open community and meeting the needs of the places where the revenue comes from. That’s what we’ve been dealing with for a significant part of our journey.
In the last five or six years that I’ve been executive director, it’s been about how do we get back to our roots and nurture that open source community while making sure that there’s a business model that can still support all of that to keep the lights on.
Renata Ávila: We share the same challenges with CKAN, a software managed and held in trust by OKFN. How should we spin while nurturing the community? How should we invest in governance? How should we invest in translation and localisation? Compared to 20 years ago, societies all over the world have become more precarious, which means, for example, that a student or volunteer who used to be able to devote time to a project now has to work three jobs to pay the bills. On the other hand, there’s basically no public funding that’s really willing to contribute. So these new austerity measures have undoubtedly had an impact on our communities. Today, bodies like the Digital Public Goods Alliance (DPGA), on which we both sit, are opening a very interesting door for collaboration on projects like ours.
So what are your thoughts on how to keep communities alive? How can we keep people coming and nurture the open communities to create value for the public good in such an unfavourable context?
Angela Oduor Lungati: The short answer is that we are still trying to find out. I can give examples of programmes that have been broadly useful in acknowledging the economic challenges while still being able to demonstrate value.
I took over Ushahidi at the beginning of the COVID-19 crisis. Surprisingly, the pandemic was a silver lining because the use of our platform skyrocketed, proving its usefulness. There was a group in Spain, Frena La Curva, who set up the platform to create a kind of mutual aid functionality. They documented that model and shared it with 22 other Latin American and Spanish-speaking countries, and it ended up being used. It’s been very helpful because we’ve been able to communicate the value of the platform in this day and age, while showing the challenges in terms of resources. Our messaging was around ‘we are a small team’, ‘here are ways you can get involved and help’, ‘you can start an instance’, ‘you can share some of your feedback’, etc. Then we combined that with participating in programmes like Google Summer of Code and Outreachy.
I mention that because we got over the barrier of entry on the first point. We’ve managed to get the volunteers paid, thankfully, through the support of the Outreachy structure programme, and I’ve actually been able to hire two people who have come out of the community. That’s all well and good. I don’t know what will help us to grow, but it’s a first step.
I think that’s why we have programmes like the Digital Public Goods Alliance. I really appreciate the wave of awareness among funders to see the value of these tools in achieving the Sustainable Development Goals, and to understand that there’s some maintenance that’s required, not just on the technical side, but in the communities that are the backbone.
I think the other part might actually be in reinventing or rethinking our engagement strategies. The way we engage, the way we motivate volunteers now is very different from the way we used to do it.
Lucas Pretti: Let me build on this question of motivation. The spirit of the open movement that Renata talked about at the beginning came with a hacker component. We used to create our own tools, but we also hacked all the other tools available, whether mainstream or not. Recently, with the growing hegemony of Big Tech and the concentration of power around them, that hacker motivation has diminished considerably. At the same time, I feel that this hegemony has passed its peak, and there is considerable awareness that the software produced by Big Tech is harmful.
At OKFN we’re constantly asking ourselves what kind of software we need to develop. What advice would you give us? How can we motivate developers to be on this side?
Angela Oduor Lungati: When it comes to the contrast with Big Tech, I think we will always be playing catch-up. The Big Tech companies have all the resources, all the manpower and, to be honest, they’re taking all the talent because of the same economics that Renata was talking about. People need to be able to put food on the table and take care of their families.
Right now it feels like we are in competition or we have to build tools that can be on par with big tech, but we don’t have the capacity, the talent or the funding to be able to work at that level. I wonder if there’s complacency or just acceptance of a fact. We may have people who are driven by passion to change things, but who have to rely on the fact that they still have to put food on the table.
But sometimes there’s an alternative view. In the Kenyan context, I see developers saying, “I’ll come in for a while, get the resources I need for a while, and then come back.”
Lucas Pretti: That would be a kind of hacking.
Angela Oduor Lungati: It could be. But I’m still waiting for that comeback. Because what I’m seeing now is a huge avalanche that’s just sucking the talent out of the non-profit sector and it’s all going into Big Tech. I know there are people in there trying to fight the good fight. But I wonder if it’s going to be a lasting game.
Renata Ávila: Absolutely. One of our hopes is that the open movement will sit down and discuss these difficult questions together, because there is part of the answer in every community. We need those answers to understand what unites us to move forward.
We’ve also had a lot of discussion at OKFN about openness as a design principle. In conclusion, I can confidently say that Ushahidi is a perfect example of an open-by-design effort from day one. You’ve been true to openness in the design of the practices, the platforms, the governance system, and so on. It is such a privilege to see a real, tangible example of what openness as a design principle can achieve in institutions, communities and as a global effort. I learned a lot from this conversation.
Lucas Pretti: Absolutely. On that note, Angela, perhaps you could say a few final words. Maybe starting with what’s next for Ushahidi?
Angela Oduor Lungati: We feel like we’ve got to a point where there’s a lot of data, I mean the butter is on the bread, but what’s the data saying? What stories are we telling? How do we make this emergence or this resume of voices more meaningful? We realised that there’s a gap between the point where you get data and the point where it actually influences change. When we try to think critically about what role we can play in that, we have to think about whether the data we have is actually representative.
When we say we are working with disenfranchised communities, can we actually attribute what disenfranchisement means? Can we break that down by gender? Can we break that down along geographical lines, social lines, economic lines? And for somebody who’s a decision-maker, it could be somebody in government or a donor, how do we make it easier for them to gain insight and make sense of the situation? Are they able to draw comparisons or similarities between some of these different areas?
We have some hypotheses about how we might do some of these things. One of the biggest is to think about creating this federated knowledge hub of Ushahidi instances, putting the data from all those instances in one place that anyone can query, but in a way that protects cultural appropriation, that takes ownership into account and makes sure that it’s not extractive, that it’s engaging and that that consent is built into it and that local laws are respected. That’s going to be very interesting to watch.
Another very big question mark is what role can we play in continuing to foster a thriving open ecosystem, when new technologies are moving at such a fast pace. That’s basically the conversation we just had. How do we also contribute to building a responsible ecosystem while all this is happening? We know that a lot of the knowledge that’s out there right now is because of all the work that’s been done by the open movement, but that’s all going into proprietary models, which can have a direct impact on motivations.
It’s still a complex challenge, but one that we’re really thinking critically about.Renata Ávila: I think we will continue the conversation because our community is very interested in that. We are very keen to help in any way we can.
In early 2016 I posted What it means to stay, a rumination on staying put in my job long-term, building community, and switching into marathon mode in my workplace. I continue to hear from folks that it resonates with you.
This post is a follow-up: supporting my wife as she exited a harmful work situation, moving nine states away, changing careers, and finding professional footing again after a long run in higher ed and academic libraries.
What happened after I wrote that post
I stayed six more years at my job. During that time:
I was promoted from line librarian to department head and did some great work that I was proud of.
I married a fellow academic at my institution. Cue the two-body problem.
COVID hit and, like many folks, I reassessed my career.
Meanwhile, my wife’s working conditions became untenable.
She went on the market and got a great job offer.
We moved nine states away.
I left my job and changed career fields twice in two years.
We made our move in 2022, and it has taken me almost two years to write this post. Writing it has been healing. It’s still not where I want it to be, but I need to just publish it so I can write about other things.
Giving myself permission to go
How did this happen? Things moved slowly ‘til they didn’t.
The COVID career reassessment
Our rapid shift to work-from-home during COVID made me realize not only that I could work from home, but that I loved it. Remote work gave me more separation between work and my personal life, not less. At the end of each day, I’d sign off work, close my laptop, and walk immediately into the kitchen to make dinner. During a time of unceasing chaos in the world, I had the immense privilege of this centering routine. It’s something I still cherish being able to do.
Go high, go deep, or get out
In the midst of intersecting global crises, a pandemic and an insurrection, I also increasingly struggled to feel that the work I was doing every day mattered. I didn’t want to climb the ladder any further, and I knew that if I wanted to leave my specialized field, it needed to happen soon.
In my post eight years ago, I wrote about a friend telling me I could “go high or go deep” in my career. Over time, I realized there was a third option: to just go.
Letting go of the idea of a career arc
I started to do research. I met with generous friends and friends-of-friends who had been working in the private sector for years. I learned the language that people used to describe their work, and how they framed problems they were trying to solve. It sounded interesting and not totally dissimilar from my experience.
I slowly began to detach myself from the idea that my career needed to go in a straight line. I gave myself permission to go, and to try something new.
The two-body problem
While I was exploring my exit from academia, my wife’s working conditions at our university continued to deteriorate, even and especially after she got tenure. Though my situation in the library was better, her experience affected me, too. It had real consequences for both of our health and well-being. I also felt disappointed and frustrated with the institution for overworking, ignoring, and ultimately turning its back on my wife.
By the time my wife got her new job offer, we’d both gotten our heads where they needed to be for us to move on. It was time to go.
Making the move
Things really fell into place once we decided to go, which made the transition a lot easier. Within a month, we sold a house, bought a house, and I got a fully remote job at a small consultancy (based partly on the connections I’d made at my library job). Moving is hard enough; we were lucky that it went as smoothly as it could have.
The hardest thing was leaving our people
The featured image for this post is a photo of our dear neighbors gathering early in the morning of our moving day to hug us and send us on our way.
Almost two years later, saying goodbye is still the part that physically aches to think about. Leaving our jobs was relatively easy; leaving the home we’d created and our web of love and support – friends, neighbors, and colleagues – hurt the most. My wife and I had collectively spent 21 years creating our community in Richmond. It was heartbreaking to go.
The second hardest thing was the identity crisis
Skip forward to the move. My wife and I were navigating big changes together: new part of the country, new city, new home, new jobs. Along with all of these big changes came some seismic identity shifts for me as I stepped into a new workplace.
For years prior, I told myself I had a distinct identity separate from my career in libraries, and to some degree, I did. But my professional identity crisis after leaving higher ed was still intense and painful.
Finding legibility
Academic librarianship was such a tidy professional identity for me. I’d established myself in my field, was a respected leader at my institution, and was confident in my work. My wife was an academic, too. Many of our friends worked at the university where we worked. All of it fit so neatly together before. Now that I wasn’t in libraries or in higher ed, what was I?
Changing career fields, I struggled to find a new way to relate to my professional identity and tell my story in a way that was legible not only to others, but to me.
This took a long time and is still a work in progress. But it was a potent and necessary reminder that I needed to embrace that I am a person who exists outside of the work I do.
Releasing the expectations
Despite the professional identity crisis, I also felt a deep sense of relief when I was able to release the expectations I didn’t even know I was holding for myself.
I stopped worrying (or even thinking) about many of the things I had found extremely important when I was working in libraries. I felt guilty, but when I could viscerally sense the tension releasing in my body, the guilt turned to relief. I exhaled. I imagine this is what it’s like for many people when they retire.
New to the job, but not new to work
Starting a new job in an entirely new field after 13 years at the same employer was scary. I wasn’t entirely sure I had the experience to do the job well, and was worried that I was stuck in my ways. By the end of the first week, though, I saw obvious areas where I could plug in and realized I brought lots of skills along with me.
Transferable skills
Many folks who have left libraries and higher ed have talked about transferable skills. Some, in particular, that I carried with me into the private sector:
Talking with people and building relationships
Managing projects and stakeholders
Recruiting, hiring, retaining, rewarding, and managing people
Facilitating meetings and workshops, and presenting to groups of all sizes
Writing for different audiences, including communicating “professionally”
Mapping out, clarifying, and streamlining workflows
Strategic planning
Understanding how technologies connect and how the internet works
Putting theory into practice for diversity, equity, inclusion and accessibility
Instructional design, web design, writing for the web, working with legacy processes and systems, data analysis, research, and so much more.
Same shit, different context
The biggest transferable skill I brought with me, though, was perspective.
I spent the first part of my career learning how to navigate ambiguity, see the forest as well as the trees, build relationships, and create good work I was proud of. Entering new workspaces, I realized I’d learned how to read patterns, relationships, power structures, issues and assets in a much different way, and to identify what was going on at an organizational level. No matter where I went, I had the maturity and x-ray vision of someone who’d seen things. I also had a much stronger sense of where I wanted my boundaries to be, and I stuck to ’em.
Knowing myself
After well over a decade of working full time, I also felt at ease about who I was, what I did and didn’t bring, and where I needed to grow. I wasn’t afraid to say “I don’t know.” Though I was apprehensive about starting something new, I was less self-conscious than I was when I first entered the professional world. I very much owned my mid-career status, rather than feeling like a total newbie.
And because all my coworkers were new to me, not folks I had worked with since I was 24, they didn’t see me as a newbie, either.
Beginner’s brain
My new company’s culture was extremely welcoming for newcomers, and I felt supported to be completely honest about how this was a big transition and a learning curve for me.
Rather than seeing me just as someone who needed to be brought up to speed, my new coworkers saw my newness as a value-add. They asked what I thought as someone with fresh eyes on the business, and we ended up implementing several changes early on based on my ideas.
It also felt refreshing to be very new at something, to feel that uncertainty again for the first time in a while, and to remind myself that this was something I was capable of handling.
I also relished learning about how businesses work, which would help me later on when (much to my own surprise) I started my own business. I felt new synapses firing.
The second quarter of my career
Early on at my new job, a coworker explained her move to our company as “the way I wanted to spend the last quarter of my career.” My coworker had carefully chosen where she wanted to spend her last few years in the workforce. She wasn’t putting pressure on herself to follow a certain career progression.
Thinking of work-life as a series of strategic moves, rather than a graph going forever up, resonated with me. Thanks to my new colleague I had words for what was happening. I was starting the second quarter of my career.
A final note on leaving academia
Anyway, all I ever meant by “the institution cannot love you” was this: whether the institution makes you feel great or horrible, it isn’t about you. Institutions aren’t choosing NOT to love you. They are choosing to reproduce themselves.
Tressie McMillan Cottom
Many smart folks have written about leaving academia. Academic and cultural heritage institutions anywhere are going to do one thing for certain: self-perpetuate at all costs. “Institutions gonna institution” is a common refrain at our house.
The more I moved into leadership positions at my previous institution, the pricklier I felt about maxims like “the institution cannot love you”, because it felt personal. But it’s not personal. Academic and cultural heritage institutions thrive when employees believe these falsehoods:
You’ll need an outside offer if you dare to ask for a raise.
If you just follow the right administrative process, justice will be served.
The institution cares about you and will protect you.
My wife’s situation brought a lot of this into sharp focus for me. I realized that, especially as a middle manager, I had believed and perpetuated many of these myths for years. Leaving academia helped me see this all more clearly and learn what’s important for me.
My departure from academia made space for my wife to heal, too. Though she’s still in higher ed, her workplace is unionized, and she has far more protections than before. And because I’ve got a foot planted firmly outside of academia, we are both a little more more grounded, hopeful and happy.
This story is to be continued. Maybe there’ll be another update in 2032. Stay tuned.
Resources
For folks sticking around to fight the good fight in higher ed: the United Campus Workers Union continues to grow its power.
I’ve started, and continue to update, a guide to getting a job outside of academia, in part because so many folks have reached out for advice. Perhaps you’ll find it useful too.
Some related posts from former cultural heritage workers that have helped me a lot:
In 2024, Brazil was honoured with the support of an Open Data Daymini-grant to host the event in the city of Belém, Pará, in the heart of the Brazilian Amazon, organised by the group Meninas da Geo.
Meninas da Geo, led by myself, a professor at the IFPA Belém campus, focuses on developing actions to include girls and women in STEM fields using geotechnologies. Over the last 5 years, we have been actively promoting open knowledge and software use, as well as geospatial data, promoting open science and collaborative mapping.
To celebrate Open Data Day, I had the full support of the DEX Entrepreneurship sector of the IFPA Belém campus, who allowed me to use their facilities for a diverse programme. This included thematic panels with three data experts, two roundtables with three presentations each, five face-to-face and online workshops, and a major mapathon to update geo-referenced data for Belém.
The theme of the event was to discuss open data for advancing the Sustainable Development Goals (SDGs) in the Amazon, with a particular focus on SDG 5, which aims to empower women through increased use of basic technologies. The discussions emphasised the use of open data for innovation and entrepreneurship, in line with SDG 11.
Special attention was given to how open data can support projects and actions to be presented at COP30 in Belém in 2025, allowing for greater involvement of local civil society. The opening of the event highlighted the importance of data quality and availability for positive research outcomes in Belém, providing a quantitative and qualitative diagnosis of the SDG indicators for the COP host city. The presence of the executive secretary of the Municipal Forum on Climate Change, Marinor Brito, bridged the topics discussed with public policies to achieve the SDGs.
In the afternoon, after lunch, a significant Mapathon of Belém took place, involving participants both in person and online. The event was recorded and made available on the Meninas da Geo YouTube channel.
Numerous institutions contributed to the event and strengthened its celebration, including the Open Knowledge Brazil Civic Innovation Ambassador Network, Youthmappers Brazil, OpenStreetMap Brazil, and others.
There was also an informal ‘Beers with Data’ gathering at the Boteco da Mata Belém, where participants were able to network and continue discussions that couldn’t be completed during the morning sessions.
The event offered online registration through its website, with a limited capacity of 160 participants. A total of 83 participants were accredited in person, along with 50 online participants, 15 speakers and 15 volunteer organisers.
The British Library suffered a major cyber attack in October 2023 that encrypted and destroyed servers, exfiltrated 600GB of data, and has had an ongoing disruption of library services after four months. Yesterday, the Library published an 18-page report on the lessons they are learning. (There are also some community annotations on the report on Hypothes.is.)
Their investigation found the attackers likely gained access through compromised credentials on a remote access server and had been monitoring the network for days prior to the destructive activity. The attack was a typical ransomware job: get in, search for personal data and other sensitive records to copy out, and encrypt the remainder while destroying your tracks. The Library did not pay the ransom and has started the long process of recovering its systems.
The report describes in some detail how the Library recognized that its conglomeration of disparate systems over the years left them vulnerable to service outages and even cybersecurity attacks. They had started a modernization effort to address these problems, but the attack dramatically exposed these vulnerabilities and accelerated their plans to replace infrastructure and strengthen processes and procedures.
The report concludes with lessons learned for the library and other institutions to enhance cyber defenses, response capabilities, and digital modernization efforts. The library profession should be grateful to the British Library for their openness in the report, and we should take their lessons to heart.
Note! Simon Bowie has some great insights on the LSE Impact blog, including about how the hack can be seen as a call for libraries to invest more in controlling their own destinies.
The Attack
The report admits that some information needed to determine the attackers’ exact path is likely lost. Their best-effort estimate is that a set of compromised credentials was used on a Microsoft Terminal Services server (now called Remote Desktop Services). Multi-factor authentication (MFA, sometimes called 2FA) was used in some areas of the network, but connections to this server were not covered. The attackers tripped at least one security alarm, but the sysadmin released the hold on the account after running malware scans.
Starting in the overnight hours from Friday to Saturday, the attackers copied 600GB of data off the network. This seems to be mostly personnel files and personal files that Library staff stored on the servers. The network provider could see this traffic looking back at network flows, but it is unclear whether this tripped any alarms itself. Although their Integrated Library System (an Aleph 500 system according to Marshall Breeding’s Library Technology Guides site) was affected, the report does not make clear whether patron demographic or circulation activity was taken.
Recovery—Rebuild and Renew
Reading between the lines a little bit, it sounds like the Library had a relatively flat network with few boundaries between systems: “our historically complex network topology … allowed the attackers wider access to our network than would have been possible in a more modern network design, allowing them to compromise more systems and services.” Elevated privileges on one system lead to elevated privileges on many systems, which allowed the attacker to move freely across the network. Systems are not structured like that today—now tending to follow the model of “least privileges”—and it seems like the Library is moving away from the flat structure towards a segmented structure.
As the report notes, recovery isn’t just a matter of restoring backups to new hardware. The system can’t go back to the vulnerable state it was in. It also seems like some software systems themselves are not recoverable due to age. The British Library’s program is one of “Rebuild and Renew” — rebuilding with fresh infrastructure and replacing older systems with modern equivalents. In the never-let-a-good-crisis-go-to-waste category, “the substantial disruption of the attack creates an opportunity to implement a significant number of changes to policy, processes, and technology that will address structural issues in ways that would previously have been too disruptive to countenance.”
The report notes “a risk that the desire to return to ‘business as usual’ as fast as possible will compromise the changes”, and this point is well taken. Somewhere I read that the definition of “personal character” is the ability to see an action through after the emotion of the commitment to action has passed. The British Library was a successful institution, and it will want to return to that position of being seen as a thriving institution as quickly as possible. This will need to be a continuous process. What is cutting edge today will become legacy tomorrow. As our layers of technology get stacked higher, the bottom layers get squeezed and compressed into thin slivers that we tend to assume will always exist. We must maintain visibility in those layers and invest in their maintenance and robustness.
Backups
They also found “viable sources of backups … that were unaffected by the cyber-attack and from which the Library’s digital and digitised collections, collection metadata and other corporate data could be recovered.” That is fortunate—even if the older systems have to be replaced, they have the data to refill them.
They describe their new model as “a robust and resilient backup service, providing immutable and air-gapped copies, offsite copies, and hot copies of data with multiple restoration points on a 4/3/2/1 model.” I’m familiar with the 3/2/1 strategy for backups (three copies of your data on two distinct media with one stored off-site), but I hadn’t heard of the 4/3/2/1 strategy. Judging from this article from Backblaze, the additional layer accounts for a fully air-gapped or unavailable-online copy. An example is the AWS S3 “Object Lock” service, a cloud version of Write-Once-Read-Many (WORM) storage. Although the backed-up object is online and can be read (“Read-Many”), there are technical controls that prevent its modification until a set period of time elapses (“Write-Once”). Presumably, the time period is long enough to find and extricate anyone who has compromised the systems before the object lock expires.
Improved Processes
The lessons include the need for better network monitoring, external security expertise retention, multi-factor authentication, and intrusion response processes. The need for comprehensive multi-factor authentication is clear. (Dear reader: if you don’t have a comprehensive plan to manage credentials—including enforcement of MFA—then this is an essential takeaway from this report.)
Another outcome of the recovery is better processes for refreshing hardware and software systems as they age. Digital technology is not static. (And certainly not as static as putting a printed book on a climate-controlled shelf.) It is difficult (at least for me) to envision the kind of comprehensive change management that will be required to build a culture of adaptability and resilience to reduce the risk of this happening again.
Some open questions…
I admire the British Library’s willingness to publish this report that describes in a frank manner their vulnerabilities, the impacts of the attack, and what they are doing to address the problems. I hope they continue to share their findings and plans with the library community. Here are some things I hope to learn:
To what extent was the patron data (demographic and circulation activity) in the integrated library system sought and copied out?
How will they prioritize, plan, and create replacement software systems that cannot be recovered or are deemed too insecure to put back on the network?
Describe in greater detail their changes to data backup plans and recovery tests. What can be taught to other cultural heritage institutions with similar data?
This is about as close to “green-field” development as you can get in an organization with many existing commitments and requirements. What change management exercises and policies helped the staff (and public) through these changes?
Cyber security is a group effort. It would be easy to pin this chaos on the tech who removed a block on the account that may have been the beachhead for this attack. As this report shows, the organization allowed this environment to flourish, culminating in that one bit-flip that brought the organization down.
I’ve never been in that position, but I am mindful that I could someday be in a similar position looking back at what my actions or inactions allowed to happen. I’ll probably be at risk of being in that position until the day I retire and destroy my production work credentials. I hope the British Library staff and all involved in the recovery are treating themselves well. Those of us on the outside are watching and cheering them on.
As of March 2024, the NDSA Coordinating Committee voted to welcome its three most recent applicants into the membership. Each new member brings a host of skills and experience to our group. Keep an eye out for them on your working and interest group calls and be sure to give them a shout out. Please join me in welcoming our new members! To review our list of members, you can see them here.
Bethany Scott, NDSA Coordinating Committee Chair
Anderson Archival
Anderson Archival seeks to join the National Digital Stewardship Alliance to expand our perspective and knowledge on the digital preservation field. As a provider of digital preservation services, we continually advocate for the digital preservation field and work to effectively communicate trends and standards with our peers and clients. Our team understands that digital preservation requires much more than simply digitizing in order to transform a collection into a powerful preservation and research tool. We are continuously looking to meet our clients where they are in their understanding of digital preservation and give them the resources they need to make informed decisions regarding their collections. Additionally, our website and blog offer valuable information on digitization and digital preservation that is available to everyone. Overall, at Anderson Archival, we are dedicated to providing top-notch digital preservation services and resources to our clients, and we are constantly striving to learn and improve our services in this ever-evolving field.
Digital Life Advisors
Digital Life Advisors applies what we perceive as digital stewardship practices to digital estate planning. We work with individuals, many of whom are older adults, to locate and organize their digital legacy assets. These assets can include photos, videos, personal writings, blogs, articles, newsletters, social media account presence, emails, computer and cloud files among other properties. We recommend password managers, digital vaults and other tools to secure and preserve our clients’ digital lives.
Mississippi Digital Library
The Mississippi Digital Library (MDL) is the collaborative digital library for the state of Mississippi. We are a network of over 50 partner institutions ranging from academic libraries and public libraries to historical societies and museums. MDL’s mission is to assist our partners in building high quality, sustainable digital collections and sharing their cultural and historical resources with researchers around the world. We are committed to teaching and educating our partners as well as the public on digital preservation and helping them determine the appropriate preservation actions for them. We are currently piloting a statewide digital preservation collaborative that will offer value added digital preservation services to Mississippi based institutions and help expand our role from education and access to preservation and sustainability of digital content.
DPLA’s Metadata Working Group has developed a workshop series designed for people working with cultural heritage data looking to deepen their understanding and practice of reparative description. Reparative description focuses on remediating or contextualizing potentially outdated or harmful language used in descriptive practices, ensuring accuracy and inclusivity (definition derived from Yale’s Reparative Archival Description).
This series will cover a wide range of topics such as representations of gender and sexuality in cultural heritage data; description strategies for problematic collections, non-English language materials, and graphic images; and the use of Traditional Knowledge (TK) labels for indigenous cultural property.
Through engaging presentations, discussions, and panels from invited speakers, participants will gain practical skills and insights to enhance their description workflows and promote a more just and inclusive environment.
Approaching reparative description for the first time can feel challenging for many of us who have the right intent but worry about having unintended impacts. Learning in a welcoming community setting can help grow our confidence and build connections. Contributed by Richard J. Urban.
Wake County Public Libraries earn Sensory Inclusive certification
On 14 March 2024, the Wake County, North Carolina Government website reported that the Wake County Public Libraries (OCLC Symbol: NXA) became the first library system in the state to earn a Sensory Inclusive certification from the nonprofit disability advocacy organization KultureCity®. The certification process ensures that Wake County Public Libraries staff are trained by leading medical professionals in how to recognize visitors with sensory needs and how to handle a sensory overload situation. All 450 permanent WCPL staff members have earned certification. Each of Wake County’s 23 libraries has been provided with Sensory Inclusive signage, weighted lap pads, and sensory bags that contain noise-canceling headphones, fidget tools, visual cue cards, feeling thermometers, and a KultureCity® VIP lanyard to create a welcoming experience. There will also be new programming including a Sensory Storytime designed to engage children who may find the regular programs to be overwhelming with smaller audiences, lower volumes, and sensory kits with headphones and fidgets.
Providing services that create a comfortable and accommodating experience for library users with sensory issues should be the norm for all libraries. I agree with Wake County Commissioner Tara Waters that programs like these move us further “in our journey toward creating a more accessible and inclusive community for all.” Contributed by Morris Levy.
Making virtual meetings neuroinclusive
Virtual meetings can cause exhaustion and anxiety (often called “Zoom fatigue”) in everyone. For neurodivergent people, these effects are often heightened because of sensory and cognitive overload. The blog post “A Neuroinclusive Approach to Virtual Meetings” by Victoria Tretis, a certified coach for neurodivergent workers. Tretis’ recommendations for online meetings include providing agendas in advance, considering the necessity of having cameras on, and using plain language by avoiding jargon and abbreviations. A Zoom blog post about inclusive online meeting practices also emphasizes the importance of a clear agenda and explains how Zoom’s avatar feature alleviates the pressure of being on camera while providing facial expressions.
As someone with ADHD, virtual meetings can be difficult for me. The amount of visual and auditory stimulation increases with virtual meetings. In an in-person meeting, I can only look at one thing at a time, e.g., the presentation screen or a person. In an online meeting, I see multiple people and presentation content all crowded together on one screen. Reducing the visual stimuli is possible but requires me to actively change settings and rearrange windows on my screen. The impact of disorganization is magnified in virtual meetings, sometimes causing headaches, dizziness, or nausea. As Tretis notes, “… when we consider that neurodiversity means 15-20% of the world think, learn and respond differently than most, neuroinclusive meetings will, quite simply, become more effective.” Contributed by Kate James.
Women’s History Month with the Towards Inclusive Excellence blog
Toward Inclusive Excellence (TIE), the blog from ALA’s Association of College and Research Libraries (ACRL), reliably brings together diverse resources to keep libraries, especially but not only those that serve higher education, abreast of ideas and initiatives that can help move society forward. To mark Women’s History Month — March in the United States — TIE makes available “Commemorating Women’s History Month with TIE and Choice Content.” Webinars, interviews, blog posts, resource lists, reviews, podcasts, and other material from the past year on women’s rights, gender-based violence, and other aspects of women’s history can be found, as well as links to similar resources from the March 2023 Women’s History Month.
For 2024, the theme of Women’s History Month is “Women Who Advocate for Equity, Diversity, and Inclusion,” according to the National Women’s History Alliance (NWHA), which helped to establish the commemoration in 1987. Then as now, the organization has been devoted to “writing women back into history.” In 2023, OCLC worked with NWHA to create the Women’s History topic page on WorldCat.org. Because of the dynamic nature of the WorldCat bibliographic database, the preprogrammed searches included on the topic page are as up-to-date as WorldCat itself. Contributed by Jay Weitz.
Through blockchain addresses used by ‘‘pig butchering’’ victims, we trace crypto flows and uncover methods commonly used by scammers to obfuscate their activities, including multiple transactions, swapping between cryptocurrencies through DeFi smart contracts, and bridging across blockchains. The perpetrators interact freely with major crypto exchanges, sending over 104,000 small potential inducement payments to build trust with victims. Funds exit the crypto network in large quantities, mostly in Tether, through less transparent but large exchanges—Binance, Huobi, and OKX. These criminal enterprises pay approximately 87 basis points in transaction fees and appear to have recently moved at least $75.3 billion into suspicious exchange deposit accounts, including $15.2 billion from exchanges commonly used by U.S. investors. Our findings highlight how the ‘‘reputable’’ crypto industry provides the common gateways and exit points for massive amounts of criminal capital flows. We hope these findings will help shed light on and ultimately stop these heinous crimes.
Their Figure 9 shows the flow of funds over time into the scammer's wallets at exchanges. This is how they estimated the $75.3B; their extremely conservative estimate is $35.1B, and their liberal estimate is $237.6B. Note the huge ~$45B increase from January 2021 to January 2023, partly driven by the cryptocurrency boom, and the slowing until January 2024. Presumably the ETF pump will accelerate the rate.
Below the fold, some commentary on this and other recent developments.
Note that these numbers are flows not the total revenue for the scammers, there is some double-counting involved as scammers move funds between their accounts at these exchanges. The $15.2B is likely much closer to revenue, because the scammers generally don't want to move significant sums into Western exchanges.
Griffin and Wei start their tracing from a collection of the wallet addresses which the scammers used to receive funds from victims:
We start with 3,256 Ethereum addresses, 770 Bitcoin addresses, and 702 Tron addresses. Most addresses are used ten or more times, and 28% of addresses are used more than one hundred times. Of these initial sets, Ethereum addresses receive $5.8 billion in funds, compared to $389 million for Tron and $373 million for Bitcoin. Given that the Ethereum addresses represent approximately 88% of the total funds, we begin by examining Ether (ETH, the native cryptocurrency on Ethereum) and token (commonly known as ERC-20 tokens) transactions on the Ethereum blockchain.
We trace victim funds in bulk and follow their paths to centralized exchange deposit addresses from January 2020 to February 2024. Figure 1 plots the resulting network for a three percent sample of nodes from the traced network and highlights many features.
First, the figure shows how crypto often originates from large exchanges where investors commonly have accounts (Coinbase, Crypto.com, and Binance) and flows into the network.
The victims need to convert fiat into cryptocurrency using well-known, trusted exchanges.
Second, funds are often swapped for Tether (known as USDT) through Tokenlon.
Tokenlon is not a mixer, similar to Tornado Cash, but "a relatively obscure decentralized exchange". The scammers' goal is partly to obscure their tracks but also to avoid the volatility of cryptocurrencies by converting to stablecoins at the first opportunity.
Fourth, transactions in amounts above $100,000 and in particular $1 million commonly transfer funds to deposit addresses on Binance, Huobi, and OKX.
Obviously, they are the offshore exchanges that lack effective KYC/AML, and in particular the one that pled guilty.
Note that this research contrasts with the tracing efforts I discussed in Tracing The Pig Butchers, which traced flows starting from a few victim reports. This research both starts from a much larger collection of victim reported addresses, and uses network analysis techniques to identify a much larger set of scammer wallet addresses. Thus it is understandable that Molly White is skeptical:
But the $75 billion number was certainly a surprise, and it's hit mainstream outlets including Time. I have to say I have some doubts about the number, particularly given other estimates have been in the low billions, but regardless, it's clear that the pig butchering issue in crypto is a multi-billion dollar problem.
But there are good reasons why Griffin and Wei would come up with much larger numbers for revenue than earlier tracing efforts; they are looking at a much larger fraction of the total scammer network. Zeke Faux's article in Time starts:
Pig-butchering scammers have likely stolen more than $75 billion from victims around the world, far more than previously estimated, according to a new study.
recently moved at least $75.3 billion into suspicious exchange deposit accounts
The paper points out that the $75.3B in flows includes some amount of double-counting:
If a network sent funds from say OKX to Binance, it would lead to the double-counting of funds. Additionally, the funds may be due to other activities of the criminal networks. ... We examine the sources of funds that later enter into these potential scammer deposit addresses and find that $40.2 billion of the $75.3 billion can be attributed to exchanges.
It is unlikely that all this movement from one exchange to another is between scammer accounts, so $35.1B is a conservative estimate.
Across all exchanges, the scammer network initiated 104,460 deposits to centralized exchanges for amounts below $10,000, most commonly in small amounts clustering at round numbers, such as $100, $200 or $500. The transaction patterns mirror the characteristics of inducement payments in pig butchering scams, which are small payments from scammers to victims used to build trust.
...
We find 83% of potential inducement payments are sent from addresses used in more than ten transactions, suggesting limited monitoring by crypto exchanges.
There is a reason for "limited monitoring by crypto exchanges". The 87 basis points the authors find on movements of $75.3B is $655M in fees over 4 years, enough to motivate turning a blind eye.
Griffin and Wei's Figure 2a shows their trace of a single victim report. Their figures use the following conventions:
Edges that are concave up represent flows moving from left to right (e.g., the curve moves as if going from 9 o’clock to 3 o’clock). Similarly, edges that are concave down represent flows moving from right to left (e.g., from 3 o’clock to 9 o’clock). Nodes are colored by identity, ... and their size is proportional to the total amount transacted. Edges are colored by transaction size and identity. Green edges are transactions from exchanges, while blue and purple are transactions to exchanges. Edges entering or exiting exchanges with darker colors represent larger transactions.
The left and right nodes are scammer wallets. The right node is a "collection node" that converts victim payments to Tether and aggregates them for onward transmission in larger amounts.
Their next step was to find other flows into the collection node, as shown in Figure 2b. Even this one step into the network produces a large number of scammer wallet addresses, the addresses to which other victims were directed to send funds. By identifying these wallets the authors generate a huge number of additional "victim reports".
Griffin & Wei Fig. 2c
Tracing the flows out of the collection nodes produces an enormous number of other scammer wallets, shown in Figure 2c, as the funds are shuffled around to obfuscate the flows.
Since scammers are unlikely to return large sums of stolen funds, we consider deposit addresses that receive more than $100,000 as more likely to be scammer deposit addresses. These addresses are rarely associated with Western exchanges, but are common within Binance, Huobi, and OKX, as well as exchanges such as Kucoin, Bitkub, and MXC. The common feature of these exchanges is that they have loose KYC procedures and are perceived to be outside of U.S. jurisdiction. To more fully understand the scope of the network, we apply “deposit address clustering” by tracking addresses that send funds into these deposit addresses and finding other recipient deposit addresses associated with the same user. To avoid capturing payments made by criminals for things like inducement payments, we exclude all connections below $100,000 and only consider direct connections.
This is where the $75.3B number comes from; it is the total inflow into deposit addresses at offshore exchanges believed to be controlled by scammers. Note again the potential for double-counting if scammers move funds between these exchanges. Deposit address clustering was published by Friedhelm Victor in Address clustering heuristics for Ethereum (Section 5.1):
To credit the assets to the correct account, exchanges typically create so-called deposit addresses, which will then forward received funds to a main address. As these deposit addresses are created per customer, multiple addresses that send funds to the same deposit address are highly likely to be controlled by the same entity.
...
The forwarded amount is often slightly less than what was received, as the exchange has to pay for the transaction costs. In most cases, deposit addresses are EOAs [Externally Owned Accounts], but they can also be smart contracts. When depositing tokens on the cryptocurrency exchange Kraken for example, users are instructed to send them to a given smart contract address, identical versions of which have been mass deployed in advance. This makes it trivial to identify all identical token deposit contracts deployed by Kraken. They are designed to forward received tokens automatically, thereby passing on the transaction costs to the user.
Victor's Figure 1 shows how this works. Wallets 0x2 and 0x3 deposit to the same deposit address at exchange A, so they have the same account at exchange A. Wallet 0x4 shares an account with 0x3 at exchange B, so all three are the same entity.
By analyzing the network graph they discover using these techniques, Griffin and Wei draw the following conclusions about money laundering:
Scammers extensively recirculate and swap funds across different addresses and cryptocurrencies. These transactions incur costs, but may help obfuscate the true source of their funds. We estimate that transaction costs for a network of this scale total to 87 basis points as a portion of outflows to exchange deposit addresses. In contrast, Soudijn and Reuter (2016) find costs of 7-16% to move physical Euro bills from Europe to Columbia and money laundering commission estimates range from 4-12% (US Treasury Department, 2002) and 10-20% (US Treasury Department, 2007). Cryptocurrencies thus appear to be a much more cost-effective channel for moving illicit funds across borders. In total, scammer swap transactions may constitute more than 58% of Tokenlon transactions since 2022. We observe large inflows from potentially Chinese victims in 2020; however, after the Chinese financial authorities banned cryptocurrency trading in late 2021, there appears to be a dramatic decrease in Chinese victims and a shift to US-based victims. Overall, in the set of addresses touched by the criminals, we find $1.172 trillion dollars of volume, 84% of which is in Tether.
This project highlights how large-scale tracing of tainted funds can help expose and understand criminal financial activity that can hopefully be used as a roadmap in other criminal contexts.
There are several other practical implications of our study.
First, organized or “legitimate” crypto exchanges serve as the on- and off-ramps for billions of dollars in criminal proceeds. Users with a crypto exchange account should realize that crypto exchange users are frequent targets of scams, and their funds are just a quick transfer away from being irreversibly lost—a risk that is far less prevalent for traditional investment accounts. Second, our findings indicate that the large players in the crypto space are likely not sufficiently protecting their customers from scams. Third, the Ethereum network appears to drastically reduce barriers for illicit financial flows of transnational organized crime. Fourth, romance scammers prefer the stablecoin Tether over other cryptocurrencies and the Ethereum network over Bitcoin. Fifth, decentralized exchanges also serve as large swapping points to exchange crypto and obfuscate funds. Crypto hedge funds and users (many based in the U.S. and Europe) who might purport to engage in “arbitrage” or “liquidity trading” (PWC, 2023) may simply be making profits by facilitating low-cost money laundering. Finally, the large centralized crypto exchanges located in jurisdictions with opaque regulatory environments (Binance, Huobi, OKX, and others) seem to be preferential potential exit points that can further finance extremely large amounts of criminal activities. Such activity has continued as of February 16, 2024, despite recent crackdowns.
Other recent developments in pig-butchering include:
Jim Browning's Inside a Pig Butchering Scam with video from inside a Chinese pig-butchering operation in Dubai that occupies at least half of a campus of 8 8-storey office buildings.
The Irrawaddy's report Surrounded by Fighting, a Myanmar Crime Hub Is Oddly Unscathed about another Chinese campus including a major pig-butchering operation, this one in a war zone on the Myanmar/Thailand border which clearly pays off both sides. It is very similar to the one Zeke Faux visited on the Cambodia/Thailand border.
Paolo Ardoino, the chief executive officer of Tether, called the report false and misleading. “With Tether, every action is online, every action is traceable, every asset can be seized and every criminal can be caught,” Ardoino said in a statement. “We work with law enforcement to do exactly that.”
Tether has cooperated with authorities in some cases to freeze accounts tied to fraud. But often by the time the crime is reported, the scammers have already cashed out.
This is more obfuscation from Tether. The paper clearly demonstrates that the scammers rapidly convert their takings to stablecoins, overwhelmingly Tether, and that they are able to use offshore exchanges as their off-ramps.
This post was written by members of the DLF Digital Accessibility Working Group. The views and opinions expressed in this blog post are solely those of the contributors and do not necessarily reflect the official policy or position of the Digital Library Federation or CLIR.
—
The DLF Digital Accessibility Working Group is excited to announce the publication of theDigital Library Accessibility Policy and Practice Guidelines. This collaborative document provides guidance for GLAM institutions (Galleries, Libraries, Archives, and Museums) to implement accessibility best practices through policies and workflows.
Some topics discussed and key takeaways include:
Policies should commit to accessibility, name standards like WCAG for each type of content, provide contact info, and define monitoring processes.
Procedures should cover ingestion, content types, software and tools used, who will perform accessibility tasks, and uphold applicable standards included in policies.
Get institutional buy-in by emphasizing the user benefits, increased usage, and legal requirements. Budget for staff time, tools, or vendor services.
Accessibility cannot be achieved in a silo, and is a shared responsibility. Distribute responsibility vertically and horizontally. Accessibility specialists should guide work, administrators supply resources, and all project participants have duties.
Integrate accessibility into all phases like planning, design, testing, and maintenance. Spread the cost throughout the lifecycle.
Follow standards like WCAG for web content, PDF/UA for documents, and include transcripts, captions, and descriptions with Audio/Visual content. Use inclusive language in metadata.
Huge thank you to everyone who made this possible: the co-authors, the Policies and Workflows subgroup, the Digital Accessibility Working Group, and the extended community of accessibility enthusiasts who provided feedback and informed our work.
With the guide complete, the Policies & Workflows subgroup welcomes new members and projects in 2024!
Want to join our group, learn more about our work, or guide the group’s future direction?
Please attend our next meeting on Fri 3/29/2024 1:00-2:00pm ET if you’d like to get involved. Email the group’s co-chairs (Wendy Guerra- wguerra@unomaha.edu ; Gabe Galson- galson@temple.edu) to receive the zoom link.
During our March meeting, we’ll continue our in-progress collaborative group exercise to identify future projects and direction.
The Learnovation Foundation Network organized the Wikidata Loves SDGs 2024 event on 7 March 2024 at the Mustapha Akanbi Library and Resource Centre in Kwara, Nigeria, to celebrate Open Data Day with mini-grant support. The event focused on enhancing and updating Wikidata items related to Sustainable Development Goals (SDGs) in Nigeria, fostering collaboration and awareness among Wikidatans, SDG advocates, and data enthusiasts.
The event boasted the presence of experienced facilitators and Wikimedia project organizers, including Barakat Adegboye, Blessing Linason, and Miracle James. The theme, “Open data for advancing sustainable development goals,” set the stage for a day of insightful presentations and hands-on activities.
Kehinde Akinsola, the Programs Lead from The Wellbeing Foundation Africa, represented by Miss Jimoh Zainab, delivered an engaging talk on the intersection of open data and SDGs, emphasizing the role of accurate data in achieving sustainable development. Hafisat Ige, a renowned Data Scientist and Women Techstar Fellow ’23, provided a deep dive into data-driven strategies for SDG advancement.
Participants, including Undergraduate Students, Educators, Librarians, Mass media and Medical professionals, engaged actively in the sessions. Despite the limitation of resources restricting invitations to only 20 out of 39 registered attendees, the event was a resounding success, with contributions spanning across various SDG-related topics on Wikidata.
The event utilized the Outreach Dashboard to track participant contributions, which included the creation of 2 new items, the editing of 12 items, and a total of 87 edits by 36 editors. The efforts of participants led to the addition of 28 new references, enhancing the reliability and depth of Wikidata’s SDG-related content.
In conclusion, Wikidata Loves SDGs 2024 not only highlighted the critical role of open data in sustainable development but also demonstrated the power of community collaboration in enriching the global data repository for the greater good. The event set a precedent for future initiatives aimed at leveraging open data for societal progress.
The challenges of transitioning to new metadata workflows have long been a concern to OCLC RLP Metadata Managers Focus Group members (What should metadata managers be learning?, Filling the bench, New skill sets for metadata managers). Recently, the group has asked me to facilitate deeper conversations about how to address these challenges. For the January 2024 session, I contacted Crystal Goldman, General Instruction Coordinator for the UC San Diego Library. Crystal’s research examines how staff in research libraries understand and apply succession planning. She notes that although there is some literature about the potential benefits of succession planning (and a call for more among library leaders/HR professionals), no comprehensive studies have been conducted across different libraries. In both her interviews and surveys, she has focused on three areas of activities (based on a framework from the Society of Human Resource Managers (SHRM)):
training and development
career planning and management
replacement planning or formal succession planning
To help us understand where Metadata Managers stand, we asked for responses to an informal survey using some of the questions from a previous instrument used in Crystal’s study of succession planning in ARL libraries.
Among both ARL libraries and Metadata Managers, formal succession planning (i.e. planning/preparing multiple individuals to potentially step into leadership roles) happens (if it happens at all) mostly at senior leadership levels. Like other ARL respondents, Metadata Managers were more likely to know about formal succession planning in their organizations if they were already managers in a leadership role. Metadata Managers identified that they engaged in replacement planning, often around key life events like expected temporary parental/medical leave and/or retirements. Even in these cases, identifying staff to fill gaps may happen in informal discussions with other managers while not directly engaging with staff who might see themselves in new roles. In the worst-case scenarios, Metadata Managers found themselves with unexpected vacancies, forcing them to promote “accidental managers” into leadership roles.
Metadata Managers reported slightly higher activity than most ARL respondents around training and development. Participants in our session felt this was unsurprising given the nature of metadata work and the changing landscape of technical developments that have been occurring. Similarly, Metadata Managers participate in some career planning and management, especially thinking about what kinds of competencies will be needed in the next five years. Forecasting those skills can inform decisions about hiring new staff members and/or providing opportunities for staff willing to seek new challenges.
When the topic of succession planning has come up in the past, I sensed that Metadata Managers were responding to broad calls to do better in this area – and perhaps felt guilty that they hadn’t made more progress. One of the most valuable things I walked away from the sessions with was a better way to tease apart the challenges we are all facing into structural, cultural, and agentive issues.
Structure
In both our sessions, Metadata Managers acknowledged the challenges of working within organizational contracts, collective bargaining agreements, or other job classification criteria. At a time when metadata is changing, these structures can require additional effort to redefine a position’s required skills and experience. This may not be feasible due to time limitations and/or limited availability from human resources staff that are trying to fill multiple open positions. In these scenarios, it can help to focus energies toward longer-range thinking about competencies.
Several Metadata Managers noted that these structures can be especially frustrating in places where metadata is transitioning. Moving away from cataloging to other kinds of next-generation metadata work can be inhibited by structural agreements that classify staff differently. As hiring managers are already struggling against economic forces to attract people into libraries with the needed computer/data science expertise, this can require additional effort to navigate. Structures also limited Metadata Managers’ agency to provide professional development opportunities to staff with aptitude/attitude for new challenges because they fall outside narrowly defined positions.
Institutional policies requiring searches to be conducted in a specific way (e.g. external national searches) can also make it hard to elevate staff with an aptitude for leadership within the organization. In Crystal’s research and in our discussions, examples surfaced of promising leaders needing to leave their organizations to advance their careers. For other types of libraries, transitioning into a management role may come with risks due to the loss of contract protections.
Culture
In many ways, succession planning in academic libraries reflects the culture of academic institutions more broadly. In principle, these are organized around merit-based systems of advancement (i.e. tenure) that find corporate-style succession planning distasteful. In these contexts, seeking external candidates holds more value than advancing staff internally. These aspects of culture are often reified into structural policies that are difficult to change (either through practice or contractual obligations).
While there is value in adding new views and voices to an organization, this practice of preferring external hires can inhibit investments in developing staff leadership skills that are key to succession planning. This approach can also create self-fulfilling feedback loops, i.e. current leadership is reluctant to invest in leadership training for non-management staff because they will not be able to advance within the organization. This is reinforced by a fear that when staff do get this training, they are likely to find it easier to leave with their new skills to another organization. These kinds of cultural attitudes are also in operation around technical skills that create a Catch-22 for both managers and staff.
Agency
Within these kinds of structures and cultures, Metadata Managers have some opportunities to exercise their agency:
How can you embed future staffing needs into other strategic planning? Rather than focusing on the advancement of an individual (i.e. traditional succession planning), how can you have transparent conversations about how to advance as a group? In the process, you may find individuals who also want to advance their leadership/technical skills. This longer-range planning can also provide the time needed to navigate structural barriers and provide opportunities to redefine job descriptions that allow for growth with the right attitude.
As a Metadata Manager, you can cultivate a climate that supports discussions about career planning beyond immediate skills development. Even having a basic discussion with your team about planning can be a good way to start the ball rolling.
It may also be helpful to have a conversation within your organization about what it means to be successful regarding the different activities that make up succession planning. Is developing staff who leave to be successful elsewhere a win or a loss? If this is not the outcome you’re hoping for, how can you change the structural/cultural roadblocks to success?
An area that would be worth additional follow-up discussion is the relationship between diversity, equity, and inclusion (DEI) efforts in libraries and succession planning activities. This intersection was outside the scope of Crystal’s work and only briefly discussed during our sessions. On one hand, formal succession planning has been viewed as a detriment to DEI because it can reinforce systemic bias about who can advance in an organization. On the other hand, conscientious use of succession planning activities can help clear away these same obstacles. In our discussion, it was noted that the culture of external searches has been tied to DEI recruitment goals. As noted, this already creates tension when successful leaders need to change institutions to advance, potentially having a detrimental effect on the retention of diverse staff. If this is a topic that you’re currently working on in your library, please reach out about how we could facilitate a future conversation among the Metadata Managers Focus Group.
This column outlines how libraries can add value to their both their digital offerings and programming while providing local music artists with a curated, low-barrier entrance into streaming media. Library-hosted digital music collections give up-and-coming artists increased exposure and credibility to listeners and open a wealth of opportunities to engage with their communities.
This paper summarizes librarian research on information visualization as well as general trends in the broader field, highlighting the most recent trends, important journals, and which subject disciplines are most involved with information visualization. By comparing librarian research to the broader field, the paper identifies opportunities for libraries to improve their information visualization support services.
Digital heritage portal interfaces are generally similar to digital library and search engine interfaces in displaying search results as a list of brief metadata records. The knowledge organization and search result display of these systems are item-centric, with little support for identifying relationships between items. This paper proposes a knowledge graph system and visualization interface as a promising solution for digital heritage systems to support users in browsing related items, understanding the relationships between items, and synthesizing a narrative on an issue. The paper discusses design issues for the knowledge graph, graph database, and graph visualization, and offers recommendations based on the authors’ experience in developing three knowledge graph systems for archive and digital humanities resources: the Zubir Said personal archive collection at the Nanyang Academy of Fine Arts, Singapore; Singapore Pioneers social network; and Polyglot Medicine knowledge graph of Asian traditional and herbal medicine. Lessons learned from a small user study are incorporated in the discussion.
To study library guides, as published on Springshare’s LibGuides platform, new approaches are needed to expand the scope of the research, ensure comprehensiveness of data collection, and reduce bias for content analysis. Computational methods can be utilized to conduct a nuanced and thorough evaluation that critically assesses the resources promoted in library guides. Web-based library guides are curated by librarians to provide easy access to high-quality information and resources in a variety of formats to support the research needs of their users. Recent scholarship considers library guides as valuable resources and as de facto publications, highlighting the need for critical study. In this article, the authors present a novel model for comprehensively gathering data about a specific genre of books from individual LibGuide pages and applying computational methods to explore the resultant data. Beginning with a pre-selected list of 159 books, we programmatically queried the titles using the LibGuides Community search engine. After cleaning and filtering the resultant data, we compiled a list of 20,484 book references (of which 6,212 are unique) on 1,529 LibGuide pages. By testing against inclusion and exclusion criteria to ensure relevancy, we identified a total of 281 titles relevant to our topic. To gain insights for future study, citation analysis metrics are presented to reveal patterns of frequency, co-occurrence, and bibliographic coupling of books promoted in LibGuides. This proof-of-concept could be adopted for a variety of applications, including assessment of collections, public services, critical librarianship, and other complex questions to enable a richer and more thorough understanding of the information landscape of LibGuides.
Despite ongoing efforts to improve database accessibility, aggregated database vendors concede that they do not have complete control over document accessibility. Instead, they point to the responsibility of journal publishers to deliver articles in an accessible format. This may increase the likelihood that users with disabilities will encounter articles that are not compatible with a screen reader. To better understand the extent of the problem, a document accessibility audit was conducted of randomly selected articles from EBSCO’s Library & Information Source database. Full-text articles from 12 library science journals were evaluated against two measures of screen reader compatibility: HTML format (the optimal format for screen readers) and PDF accessibility conformance. Findings showed inconsistencies in HTML format availability for articles in the selected journals. Additionally, the entire sample of PDF articles failed to meet the minimum standard of PDF Universal Accessibility of containing a tagged structure. However, all PDF articles passed accessibility permissions tests, so could be made accessible retroactively by a third party.
This paper investigates the potential of the Gamified Metaverse as a platform for promoting library services. The study compares the effectiveness of a traditional library program with a Metaverse-based library program in terms of knowledge acquisition and library anxiety. The research also examines students’ perceptions of implementing gamification within the context of the Gamified Metaverse platform. A mixed-methods approach was adopted, including pre- and post-test analysis, statistical analysis, and qualitative data collection. The results indicate that both the traditional and Metaverse-based library programs effectively increased the participants’ knowledge, with no significant difference between the two approaches. However, the Metaverse-based program was found to be less effective in facilitating interaction with librarians and reducing library anxiety. Additionally, students expressed positive perceptions of implementing gamification in the Gamified Metaverse platform, finding it engaging and motivating. These findings contribute to the understanding of the effect of the Metaverse as a tool for promoting library services and enhancing knowledge acquisition. However, it is not as effective in reducing library anxiety, particularly in terms of interaction with librarians and staff. It should be noted that the platform may have limitations such as high costs and potential side effects of virtual reality, making it more suitable as an additional tool for promoting library services, taking into account its feasibility and potential benefits for specific student populations and larger libraries.
Technology in libraries has played an essential role in serving today’s communities. This study provides an overview of the integrated library systems/software (ILSs) used in libraries in South Sulawesi, Indonesia. It aims to highlight the strengths and possibilities of ILSs and briefly explain their advantages and disadvantages along with the cost of implementation. The data was gathered from questionnaires sent via an online survey and from direct interviews with certain academic libraries over the period of 2019 to 2020. Fifty-three of 67 libraries that fulfilled the study have implemented an ILS. To deeply understand the application, a direct interview with some libraries was conducted to learn the advantages and disadvantages. The result of the study showed that the most used ILSs are SLiMS and INLISlite and other programs like Apollo, Athenium Light, Simpus, Spektra, Jibas, KOHA, and Openlibrary. The budget spent is an average of 300 USD. While the ILSs have helped these libraries improve services, IT expertise and adequate resources are needed, especially when the systems present problems. An easy-to-use system that costs less will potentially be used in this area of research. This study will be particularly helpful for any library in Indonesia. These findings may also be generalized to libraries in other countries facing economic and technological similarities.




















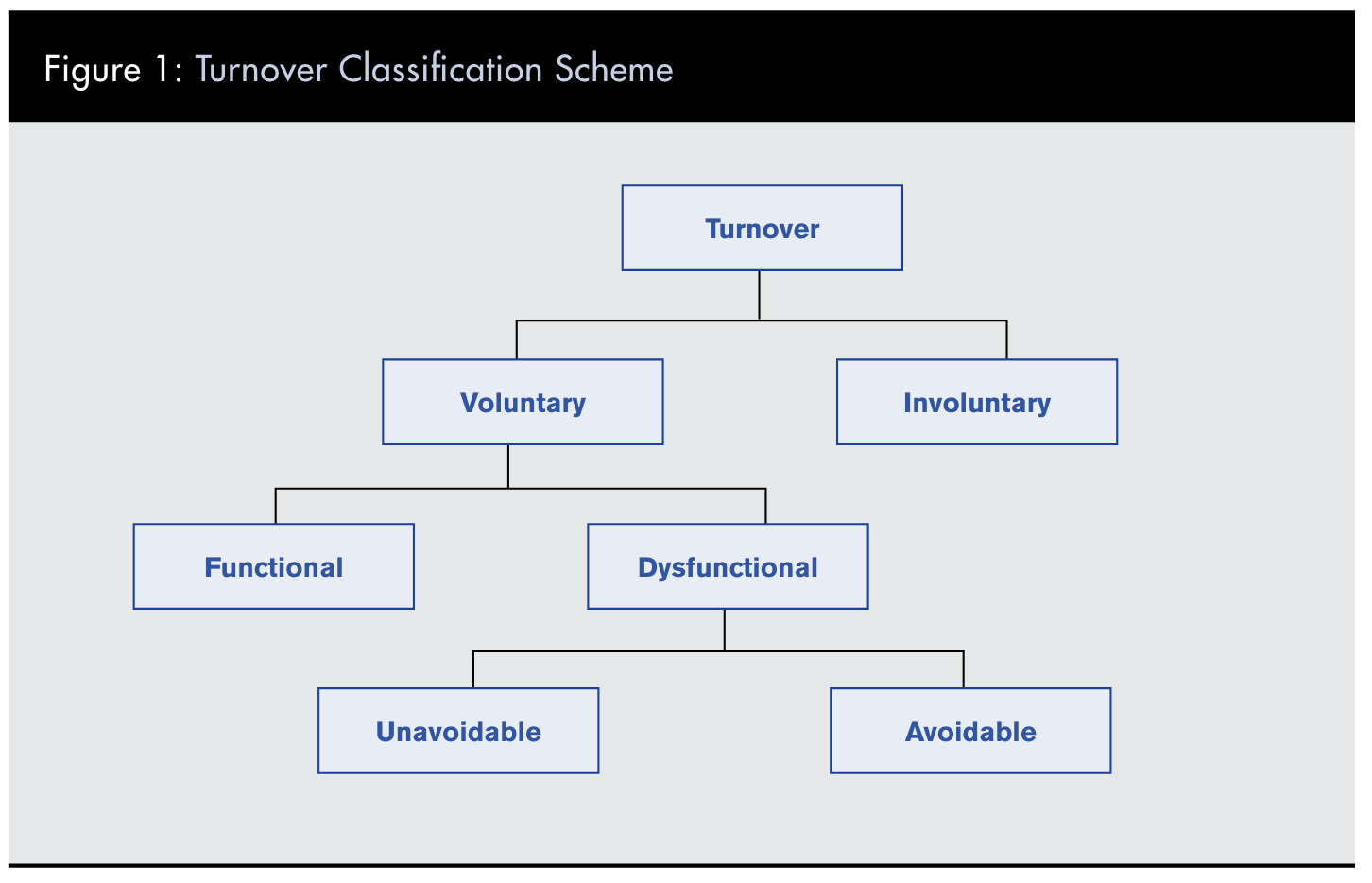 Figure 1: Turnover Classification Scheme
Figure 1: Turnover Classification Scheme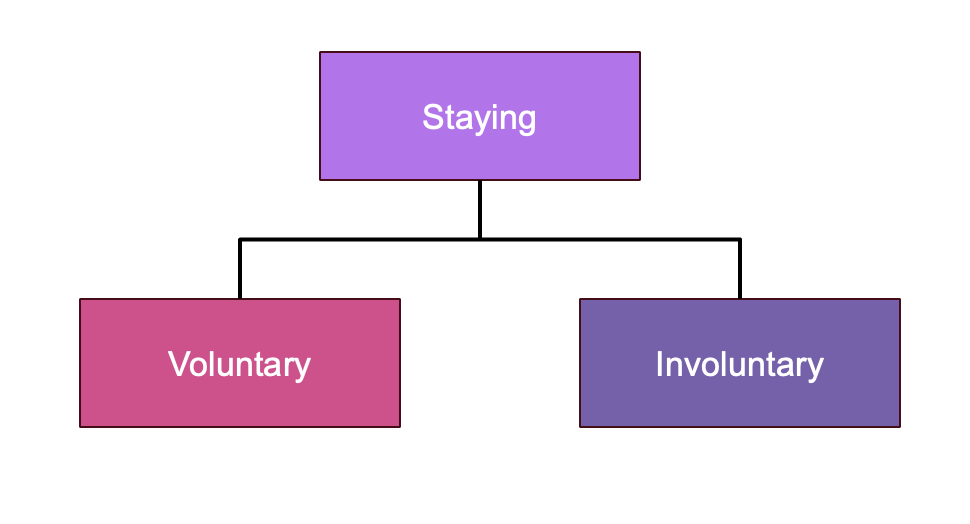 Figure 2: Voluntary and Involuntary Staying
Figure 2: Voluntary and Involuntary Staying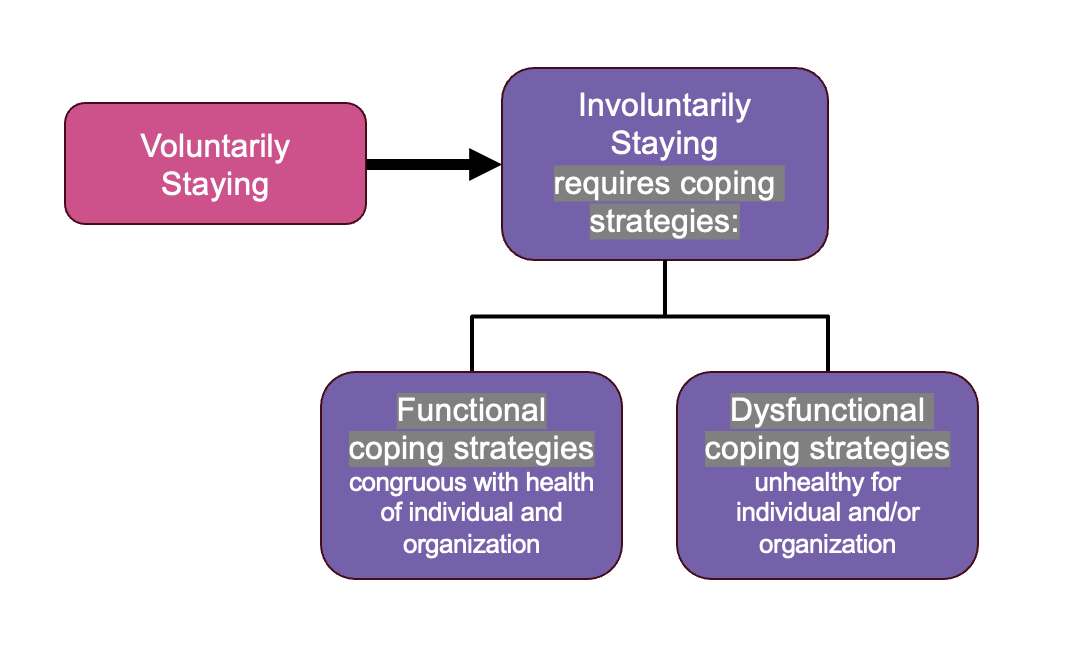 Figure 3: Functional and Dysfunctional Coping Strategies
Figure 3: Functional and Dysfunctional Coping Strategies




































 Official poster announcing the partnership between UPRIYM and TSP
Official poster announcing the partnership between UPRIYM and TSP Tiklop Society of the Philippines (TSP) and UPRI YouthMappers before deploying for the short field session
Tiklop Society of the Philippines (TSP) and UPRI YouthMappers before deploying for the short field session Street-level images in Village A (UP Diliman) uploaded at Mapillary
Street-level images in Village A (UP Diliman) uploaded at Mapillary








 certification
certification 













{kind=link}
{kind=link}
{kind=link}